Machine Learning 2022SP HUNG-YI LEE
机器学习笔记
[toc]
Lecture 1
Colab的使用
首先是Colab中的两种代码块的语法形式:

谷歌硬盘的使用:
1 | |
Linux命令(记得前面都要加!):
ls: 列出当前目录中的所有文件
ls -l: 列出当前目录中所有文件的详细信息
pwd: 输出工作目录
mkdir <dirname>: 创建一个目录 <目录名>
cd <dirname>: 移动到目录 <目录名>
gdown:从谷歌驱动器下载文件
wget:从互联网下载文件
python <python_file>:执行 python 文件该系统使用:
如果空闲超时(90 分钟,有时会发生变化)或屏幕变黑,Colab 将自动断开连接。
如果您的 GPU 使用量达到 12 小时,您的帐户将被停止一段时间
机器学习的基本概念
机器学习的本质其实是:寻找函数。我认为是给出一定的输入与输出,训练出一个所谓的“函数”,可以用于预测与判断。
而这种寻找的函数可以分为三大类:
-
Regression(回归问题)
回归问题多用来预测一个具体的数值,如预测房价、未来的天气情况等等。例如我们根据一个地区的若干年的PM2.5数值变化来估计某一天该地区的PM2.5值大小,预测值与当天实际数值大小越接近,回归分析算法的可信度越高。
-
Classification(分类问题)
分类问题是我们日常生活中最常遇到的一类问题,比如垃圾邮件的分类,识别我们所看到的是汽车还是火车抑或是别的物体,再或者去医院医生诊断病人身体里的肿瘤是否是恶性的,这些问题全部都属于分类问题的范畴。
-
Structured Learning(结构化预测)
会得到一个序列,一个句子,一个图,一颗树。经过训练所得到的函数得到的结果并非回归所得的预测或者分类中的类别。
一个简单的例子
目标:给出前一天的播放量预测后一天的播放量。
分析:要完成这个任务我们首先要将现有的播放量作为输入,将后一天的播放量作为输出来构造一个函数。接下来便要决定的就是这个函数的模样和其中参数的取值。
1.方程的设立
我们首先根据自己的Domain Knowledge(领域知识)得出一个基本的函数方程:
$$
y=b+wx_1
$$
因为x1为今天的播放量,y为明天的播放量。他们之间的比例系数为w,再加上一个修正因子便可以得到y。w和b都是待定参数,我们称w为weight(权重),称b为bias(偏移量)。
2.定义损失函数
损失函数的由来便是当我们的预测与真实值的偏差,而这些偏差的由来便是这些参数的改变。所以损失函数的输入为所有求解方程的参数。在这个例子中我们的损失函数为:
$$
L(b,w)
$$
所以在我们给出的模型中,对每一个样本点的损失函数的值求和便可以得到整个模型的损失。对于上述例子我们就可以得到整体模型的Loss为:
$$
e=\left| y-\overline{y} \right|,,OR,,e=\left( y-\widehat{y} \right) ^2
\
L=\frac{1}{N}\sum_n^{}{e_n}
$$
在上述方程中上面的两个e分别为:
-
mean absolute error (MAE)
绝对误差
-
mean square error (MSE)
均方误差
除了这两个之外,如果我们的y是概论分布的话,其实我们应该用Cross-entropy(交叉熵)。
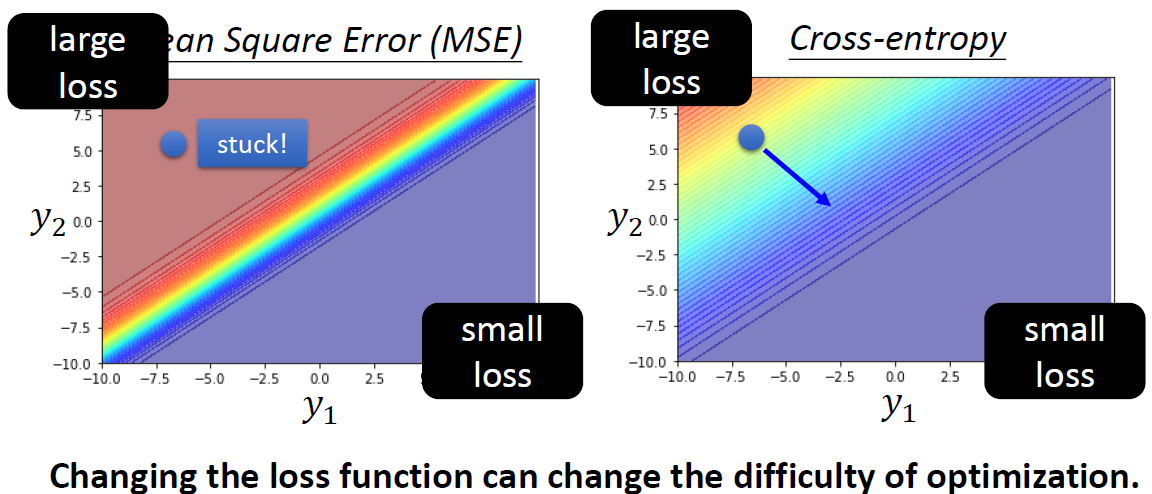
在我们得到了整个模型的Loss时候,就可以开始优化模型了。当然,我们优化的方向是向Loss更小的方向:
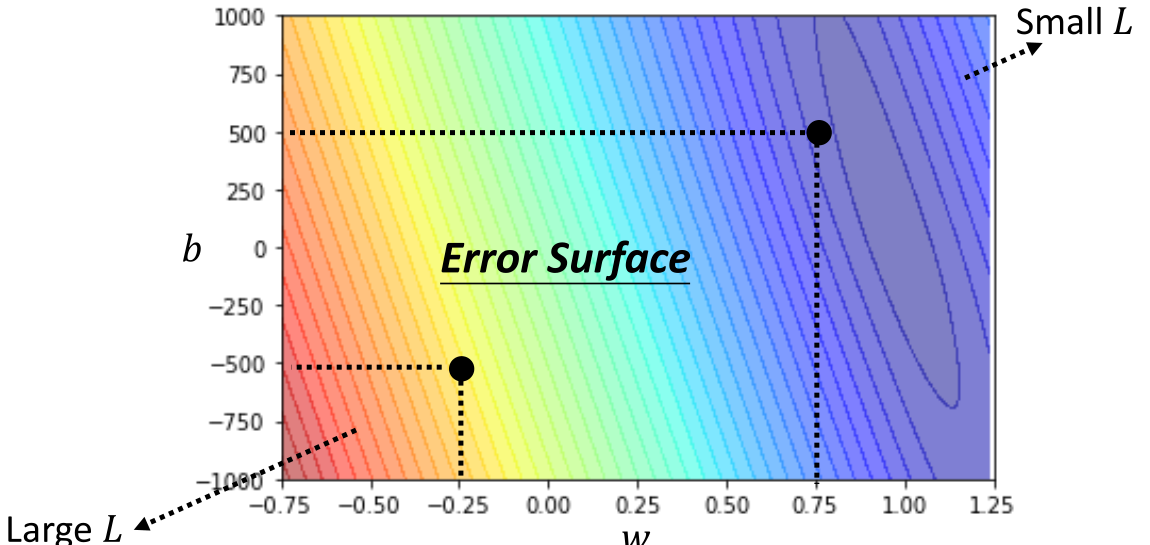
由上图所示,红色区域的Loss最大,蓝色区域的Loss最小。在该中状况下,我们按照向最小Loss的方向移动。
3.优化参数(Loss最小)
接上一个步骤的最后,我们利用梯度下降的方法求出Loss最小的地方。在一维图像中,我们可视化该步骤:
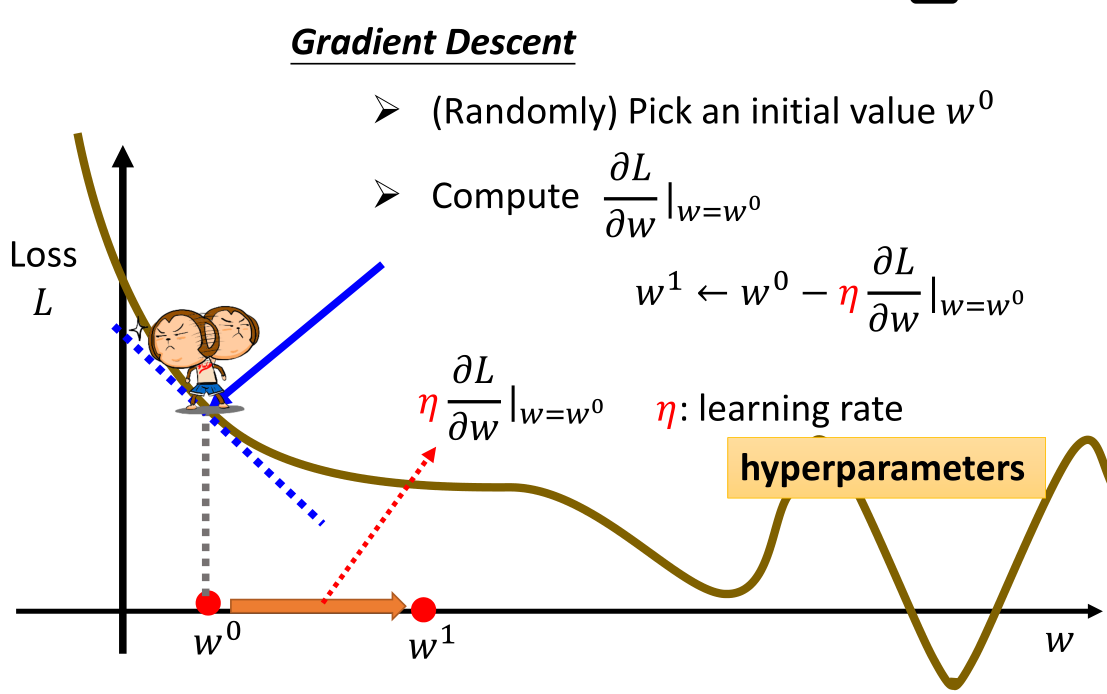
我们可以看到梯度下降的方法即是求解最小值的一个方法,在课堂上老师说到其实不用担心局部最优解的问题,会在后续的课程中进行解释。上图中还值得一提的是,每一次下降的步长即使学习率。
扩大到两个参数,我们得到梯度下降的方程:
$$
w^1\gets w^0-\eta \frac{\partial L}{\partial w}|{w=w^0,b=b^0}
\
b^1\gets b^0-\eta \frac{\partial L}{\partial b}|{w=w^0,b=b^0}
$$
不断地迭代这个方程最后得到的就是就是最小的Loss也是当前算法下的最优模型。
到此为止我们建立了一个机器学习的简易模型。
对上例的改进
贴合实际情况想想,也许播放量的决定因素并不止前一天的播放量,或许是以一周为周期进行的变化,所以我们可以不仅仅考虑一天数据作为输入,我们多考虑几天:
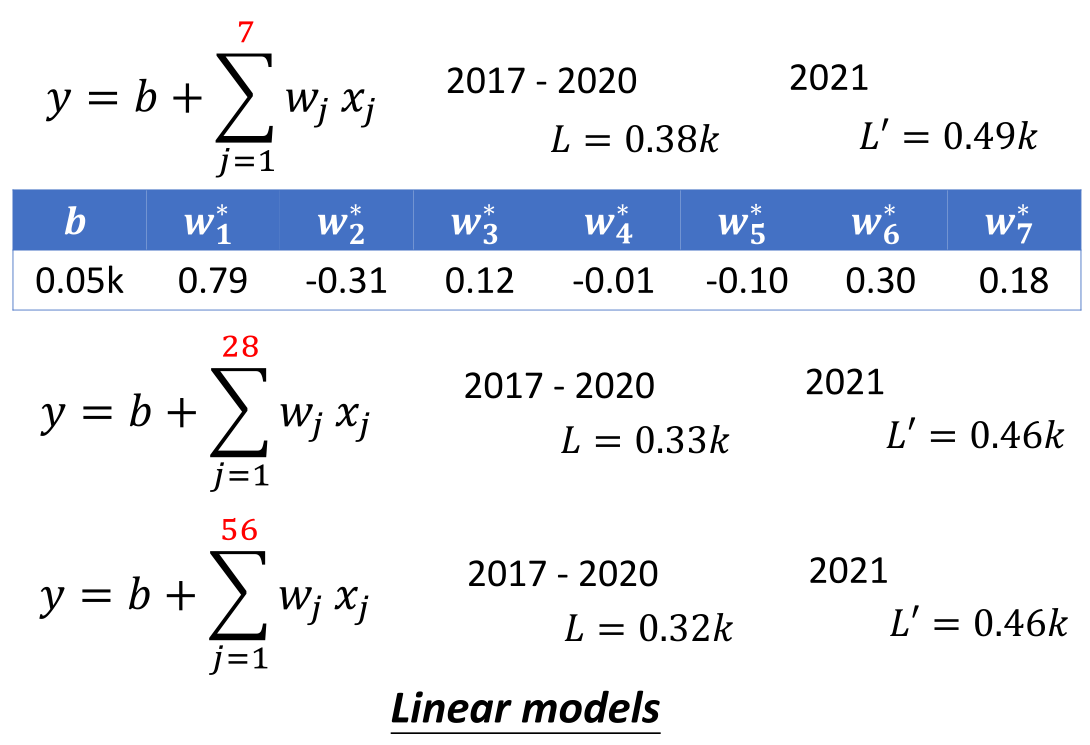
我们通过Loss可以看到,确实,通过增加输入数据的天数,我们改进模型可以使模型的误差减小。
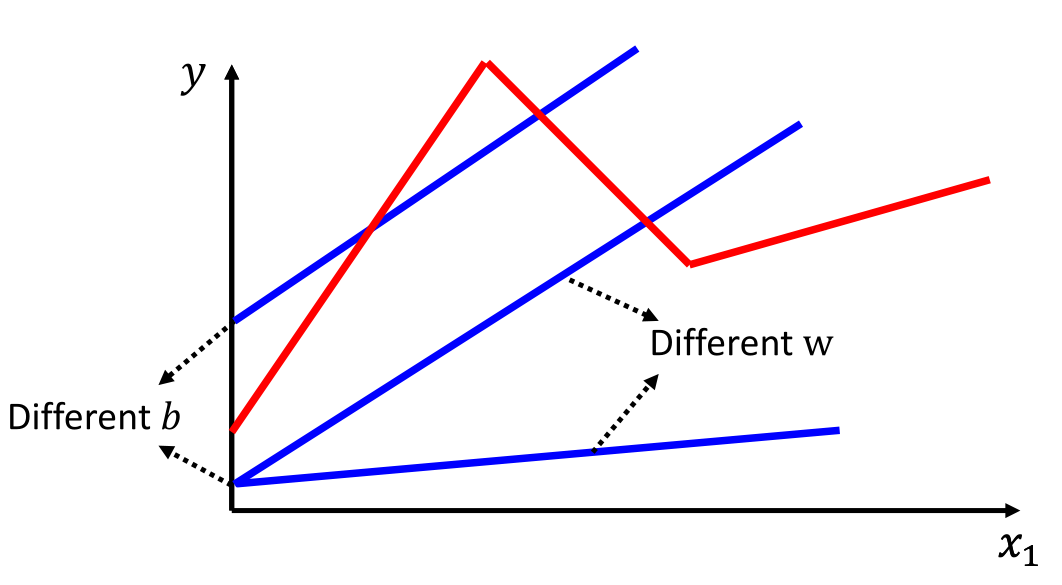
通过上面两个模型的建立与求解,我们注意到该模型只能进行线性预测,因为我们的模型一开始提出的函数时一个一次函数:
$$
y=b+wx_1
$$
在图像上表现为一条直线,联系实际我们知道这个模型太过于简单了,并且数据并不一定都是成这种简单的线性增长,如下图所示:
我们模型的无论如何调参,都无法“弯曲“,所以我们需要一个可以分段的函数进行建模。
现在问题就变成了如何将红色简化成蓝色线段的形式,观察到每一个小分段都是由一次函数组成,我们猜想许多个函数:只在某一个区间内有变化,其余全部为0,得到如下图所示:
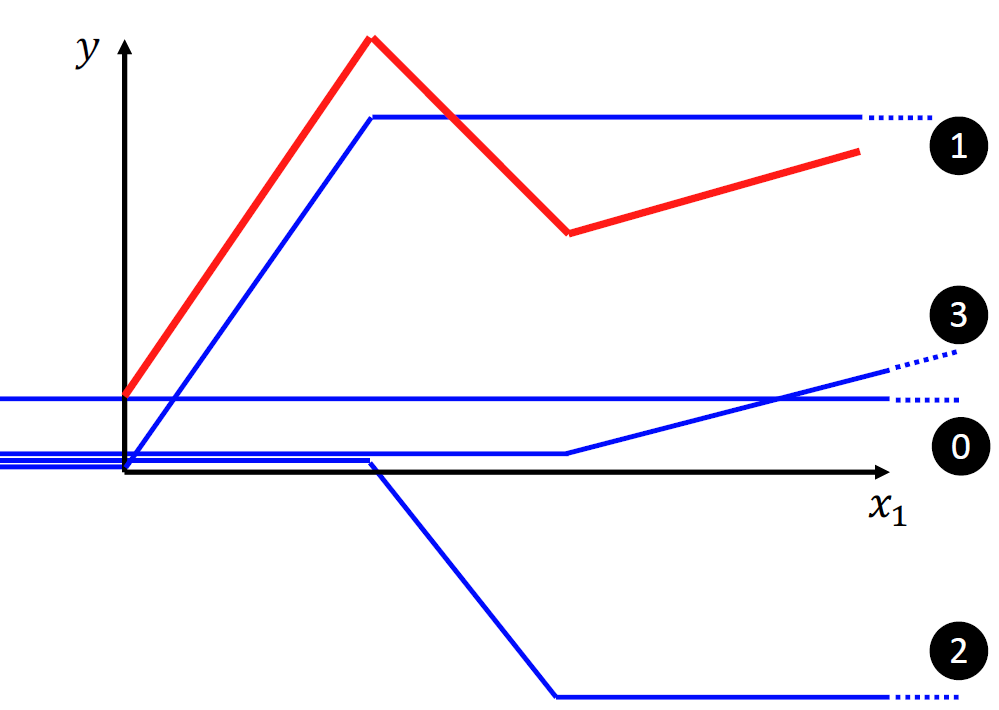
我们发现红色线段可以由许多蓝色线段进行替代,我们将蓝色线段抽象出来,得到蓝色线段的特征,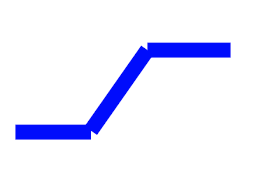
在数学上我们有Sigmoid函数可以近似该函数,同样这个带有棱角的分段蓝色函数就被叫做Hard Sigmoid我们观察Sigmoid函数的特征:
我们对于该函数简写成:
$$
y=c\frac{1}{1+e^{-\left( b+wx_1 \right)}}
\
=c,,sigmoid\left( b+wx_1 \right)
\
$$
所以我们便可将红色线段表示为:
$$
y=b+\sum_i{c_i,,sigmoid\left( b_i+w_ix_1 \right)}
\
$$
再考虑到不同线段由参数影响的变动,我们将x1不在固定,得:
$$
y=b+\sum_i{c_i,,sigmoid\left( b_i+\sum_j{w_{ij}x_j} \right)}
\
$$
在老师给的PPT上有更为详实的介绍:

在下面的这个图中,注意蓝色框中的元素,以及后面括号中的w与x所产生的原因。
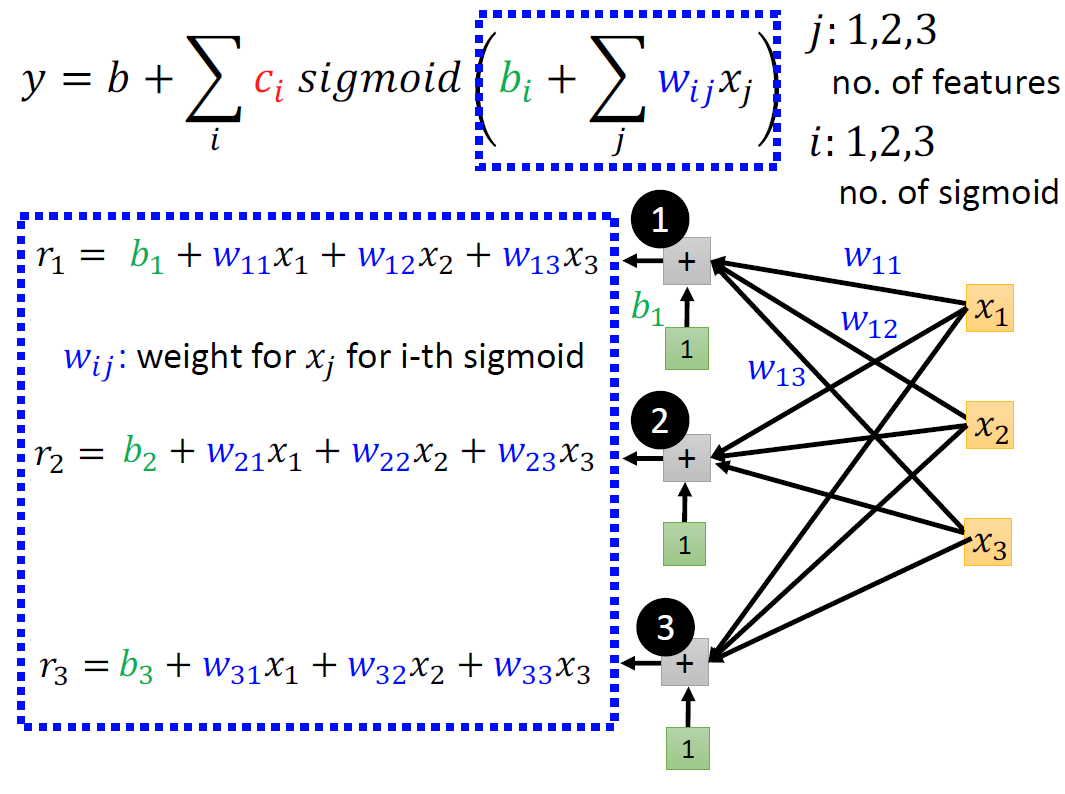
通过线性代数中的矩阵知识,我们改写算式:
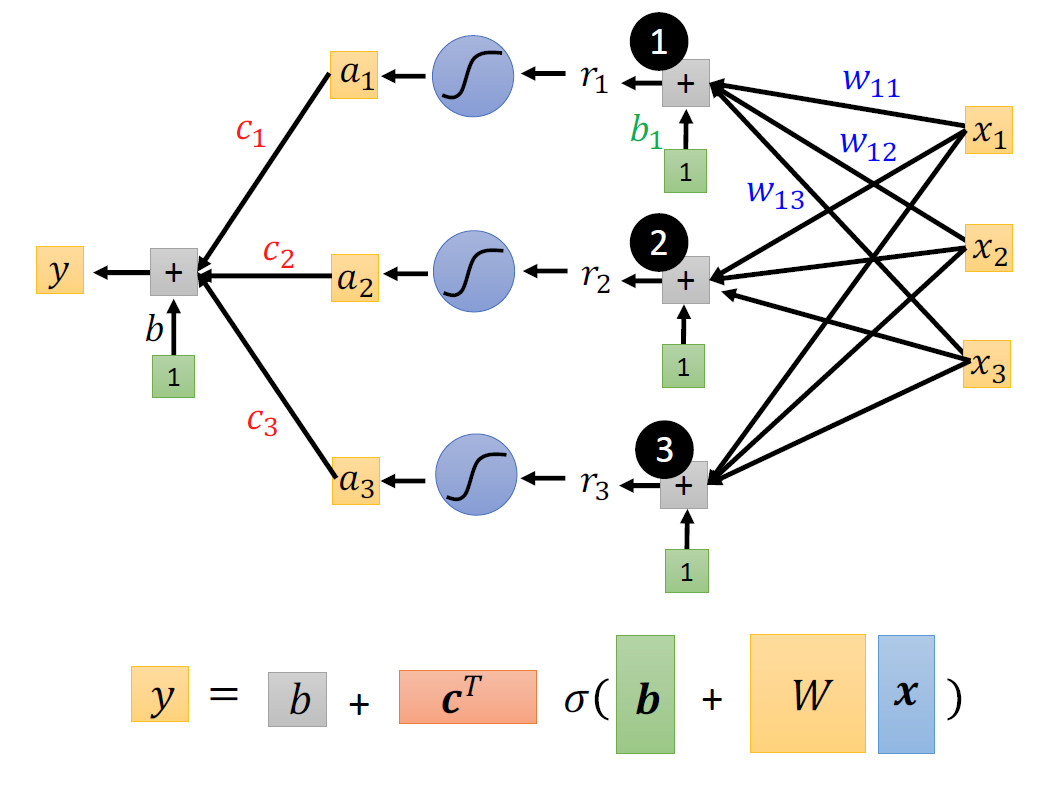
注意在该表达式中,那些量是需要计算机帮我们寻找的。仔细就会发现除了x和y都是需要计算机需要帮我们计算的。回顾我们上一次将那个线性模型进行建模之后,我们所需要进行的下一步便是计算损失函数。沿用上一次的方法我们将计算机所有需要帮我们确定的变量列成一个向量,所以损失函数即为如下:
$$
\theta =\left[ \begin{array}{c}
\theta _1\
\theta _2\
\theta _3\
…\
\end{array} \right]
\
L\left( \theta \right)
$$
在设计完损失函数后,我们便要对模型设计优化算法,经典的算法依旧是梯度下降:
我们随意取上面公式的一个值,然后求梯度。接下来开始迭代,直到梯度下降到结束。下述公式中,g为梯度(gradient)。
$$
g=\left[ \begin{array}{c}
\frac{\partial L}{\partial \theta 1}|{\theta =\theta ^0}\
\frac{\partial L}{\partial \theta 2}|{\theta =\theta ^0}\
\vdots\
\end{array} \right]
\
\left[ \begin{array}{c}
\theta _{1}^{1}\
\theta _{2}^{1}\
\vdots\
\end{array} \right] \gets \left[ \begin{array}{c}
\theta _{1}^{0}\
\theta _{2}^{0}\
\vdots\
\end{array} \right] -\left[ \begin{array}{c}
\begin{array}{c}
{\color{red} \eta }\frac{\partial L}{\partial \theta 1}|{\theta =\theta ^0}\
{\color{red} \eta }\frac{\partial L}{\partial \theta 2}|{\theta =\theta ^0}\
\end{array}\
\vdots\
\end{array} \right]
\
$$
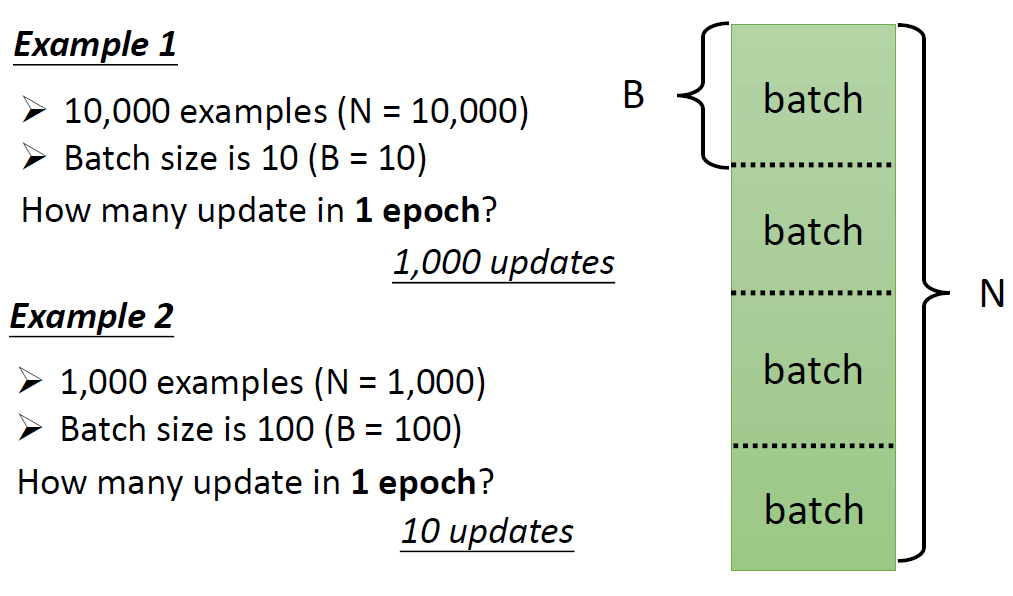
实际上我们在做梯度下降的时候,我们会有一个很大的数据集。我们将这一大批资料分成batch(一捆,一组),batch是随机分成的。
在原先的情况下我们将所有的数据集拿去训练会得到一个Loss,在现在不同的batch可以得到不同的Loss。每一次更新参数就叫做一次update。我们把所有的batch都训练过一遍叫做一个Epoch(世纪)。
Hard sigmoid
上一个问题中为什么我们要用平滑的sigmoid函数,拟合Hard sigmoid,我们能不能直接使用Hard sigmoid进行呢?
我们仔细观察这个图像我们看到其实我们可以用两个分段函数进行组合:
$$
\max \left( 0,b+wx_1 \right)
\
\max \left( 0,b’+w’x_1 \right)
$$
便可以得到我们想要的蓝色线段:
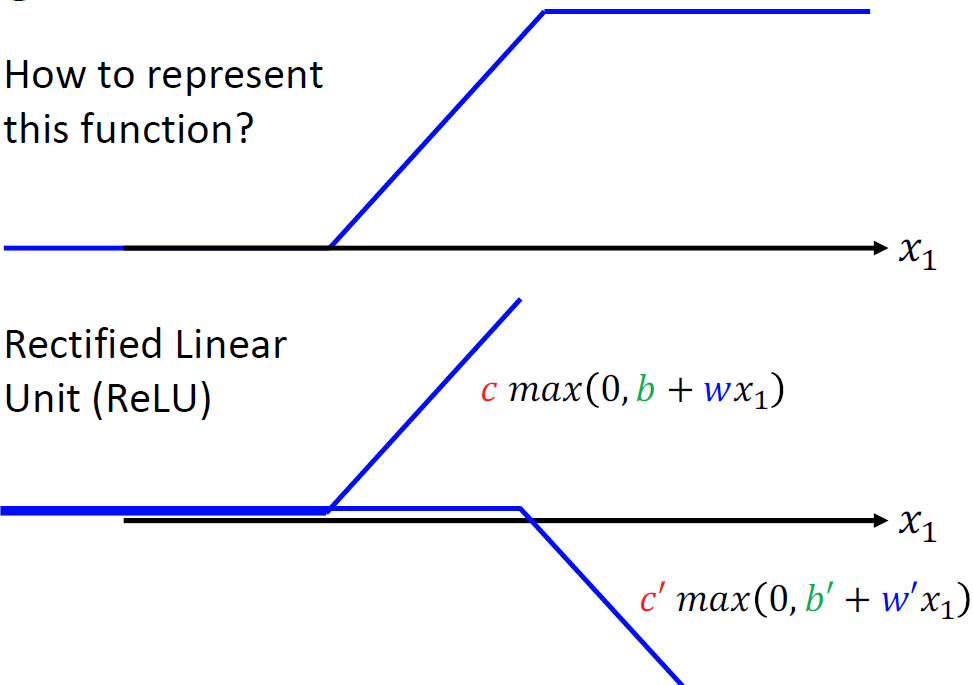
当我们进行这种转换: Sigmoid :arrow_right: ReLU (Rectified Linear Unit)。我们公式会变成:
$$
y=b+\sum_i{ {\color{red} c_i}}sigmoid\left( {\color{red} b_i}+\sum_j{ {\color{blue} w_{ij} }x_j} \right)
\
\downarrow
\
Activation,,function(激活函数)
\
\uparrow
\
y=b+\sum_{ {\color{red} 2}i}{ {\color{red} c_i} }\max \left( 0,b_i+\sum_j{ {\color{blue} w_{ij} }x_j} \right)
\
$$
多层的神经网络
回到我们上面的步骤,我们通过输入x得到了一个相对的a,如下图:
我们进一步思考将输出的a再叠加一层,重复同样的步骤,如下图所示:
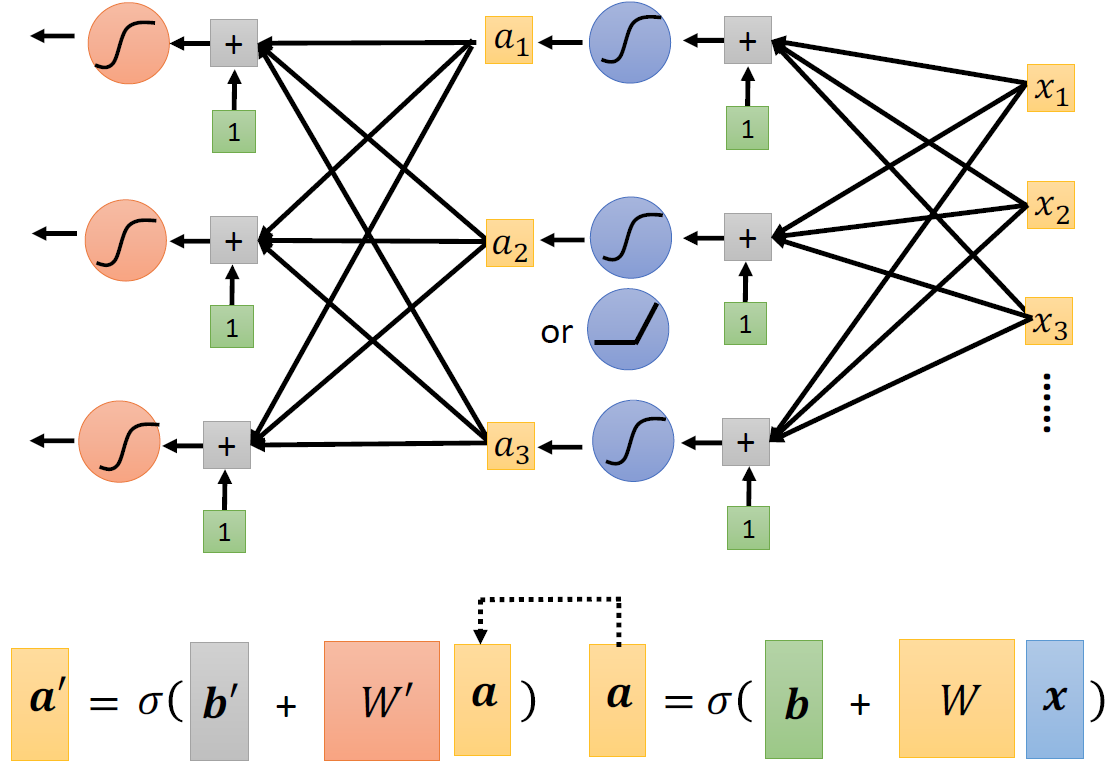
最后只得一提的是:Hyper Parameter(超参数)。
机器学习模型中一般有两类参数:一类需要从数据中学习和估计得到,称为模型参数(Parameter)—即模型本身的参数。比如,线性回归直线的加权系数(斜率)及其偏差项(截距)都是模型参数。还有一类则是机器学习算法中的调优参数(tuning parameters),需要人为设定,称为超参数(Hyperparameter)。比如说神经网络的层数,Learning Rate(学习率),几个sigmoid,Batch size。
Lecture 2
调优模型的思路
第二节课一开始,便是教会我们如何调优,在老师的PPT上有这个图:
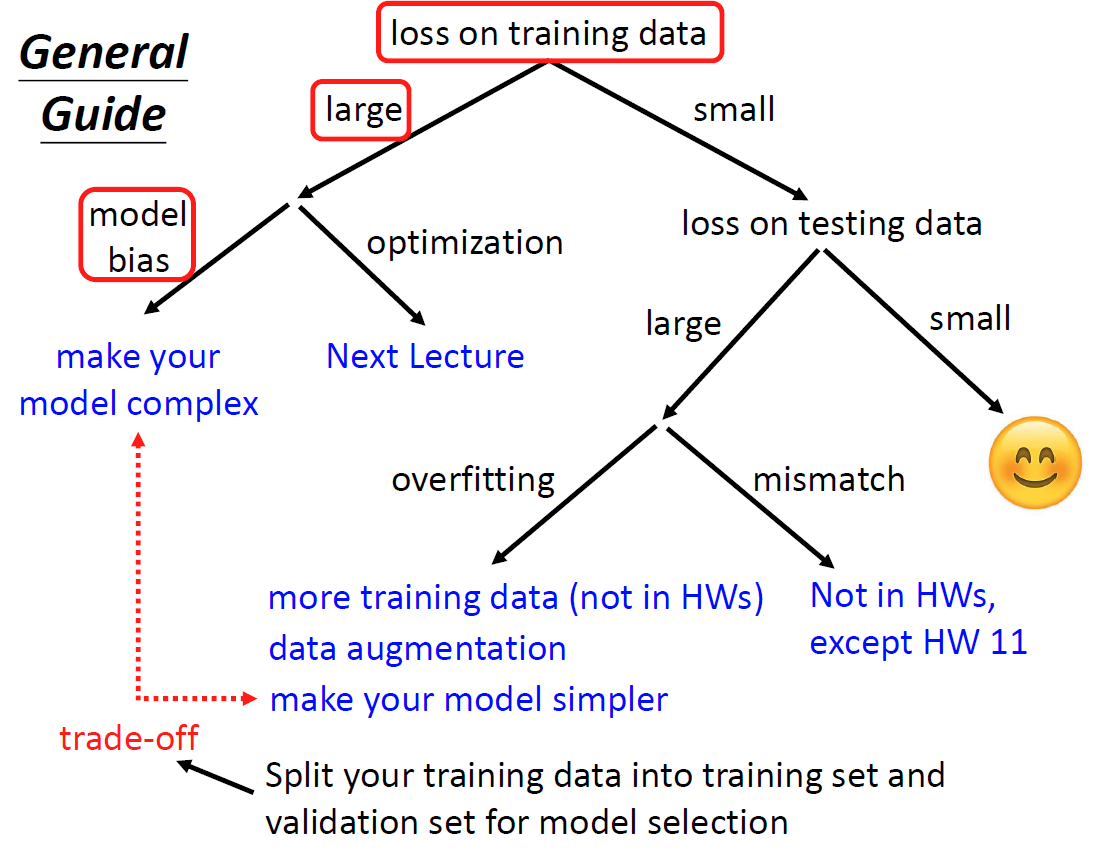
我们知道,在验证一个模型的时候,要先进行对训练集数据的检验,不能一味的对测试集进行检验。
训练数据Loss过大
在我们发现对训练数据Loss过大的时候,我们有两种猜测:
-
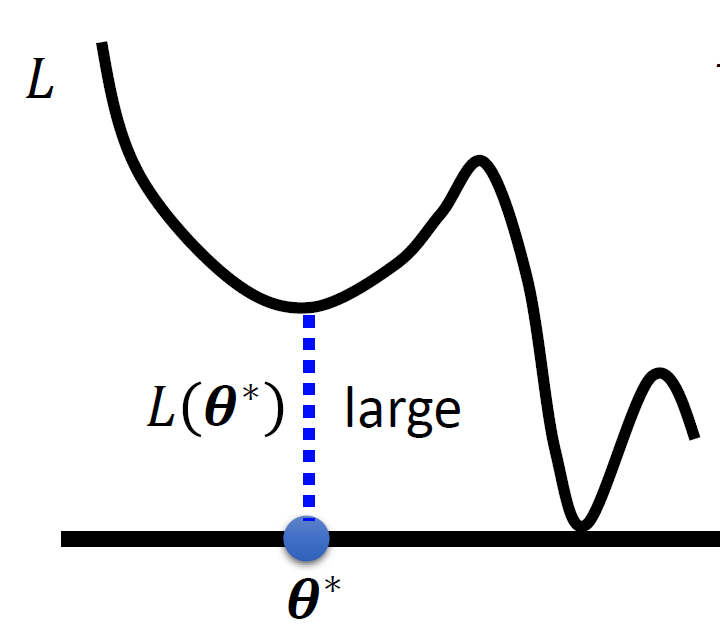
模型过于简单(model bias)
例如,当我们的数据分布是二次函数的时候,我们始终用线性模型进行拟合的化,无论怎么调参都不会达到一个期望的Loss
解决方法是,重新设计模型,使得模型具有跟具有弹性,接上面的例子,如果我们改用二次函数或者三次函数进行拟合。
-
模型的调参程序无法达到最优解(optimization)
昨天提过,我们使用的方法也许会陷入局部最优解,所以会导致Loss增大。
那我们接下来就要判断到底是哪一种方法使得Loss增大到底是模型简单还是收敛方法有误。老师上课举了一个例子:当我们使用56层的神经网络与26层的神经网络分别检测他们的Loss,我们可以发现,56的Loss更加的高。在几年前,人们认为这是过拟合的问题,其实不是。我们假设在56层的神经网络中,有30层都是直接输出,不处理输入输出,其实是可以达到26层的Loss的,所以其实不是过拟合的问题(over-fitting)。
在检测中,我们我们需要检测Loss的时候,可以减少神经网络的层数,或者简化模型,对比简化后的模型的Loss是不是减少了。如果减少了就说明我们的模型的调优程序没有找到最优解。
训练数据Loss过小
当我们的训练数据的Loss小的时候我们不能就此认为这个模型就是完美的,要对测试数据进一步进行检验。如果这个时候我们发现对于测试集的数据Loss过大,我们就可以说这个时候发生了过拟合。过拟合的图示如下:
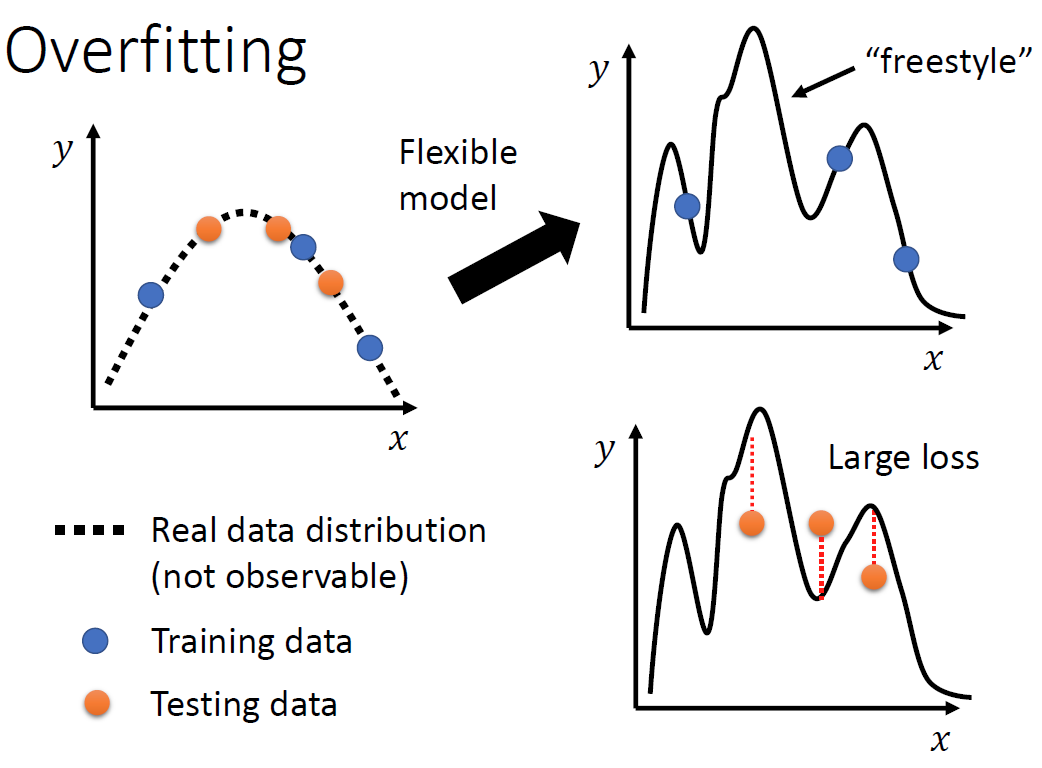
那么我们对于过拟合的数据如何处理呢?同样也是有两种办法:
- 增加更多的数据
- 数据增强(Data augmentation,使用原数据进行变换增加更多的数据)
- 限制模型
其实前两个方法是殊途同归的,都是增加机器的学习样本,使得拟合的点位增多,减小过拟合现象。第三个方法其实就相当于我们限制好该模型只能用二次函数进行调参或者指数函数。这样就可以避免上图右下角的过拟合模样。那如何固定这个函数或者模型就取决于我们每个人对于模型的理解。比如说CNN神经网络就是更具图像的特点固定模型的部分参数。
我们根据感觉可以得到一个训练集上的Loss与测试集上的Loss随着时间变化的图像:
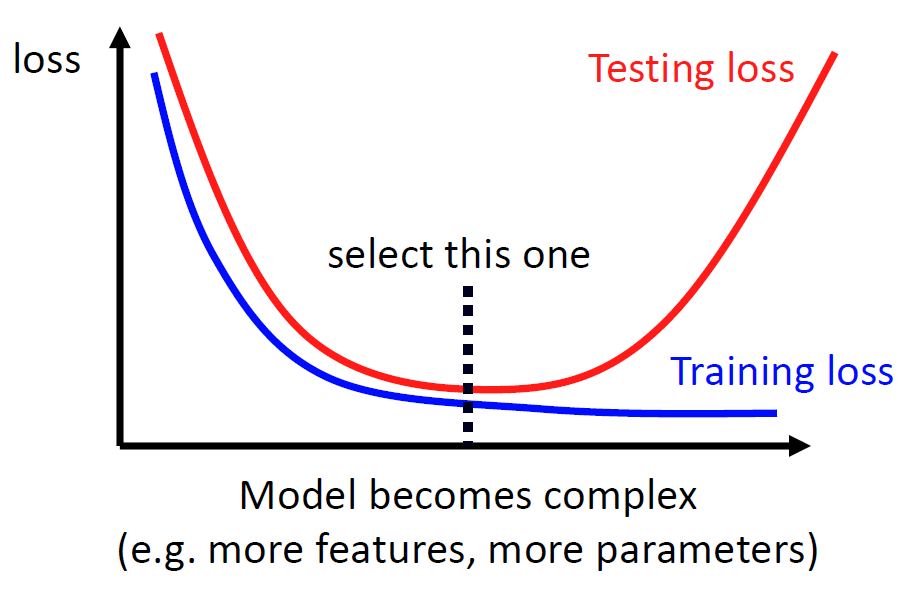
而当我们无法增加原始数据量的时候,我们可以使用交叉验证(Cross Validation):
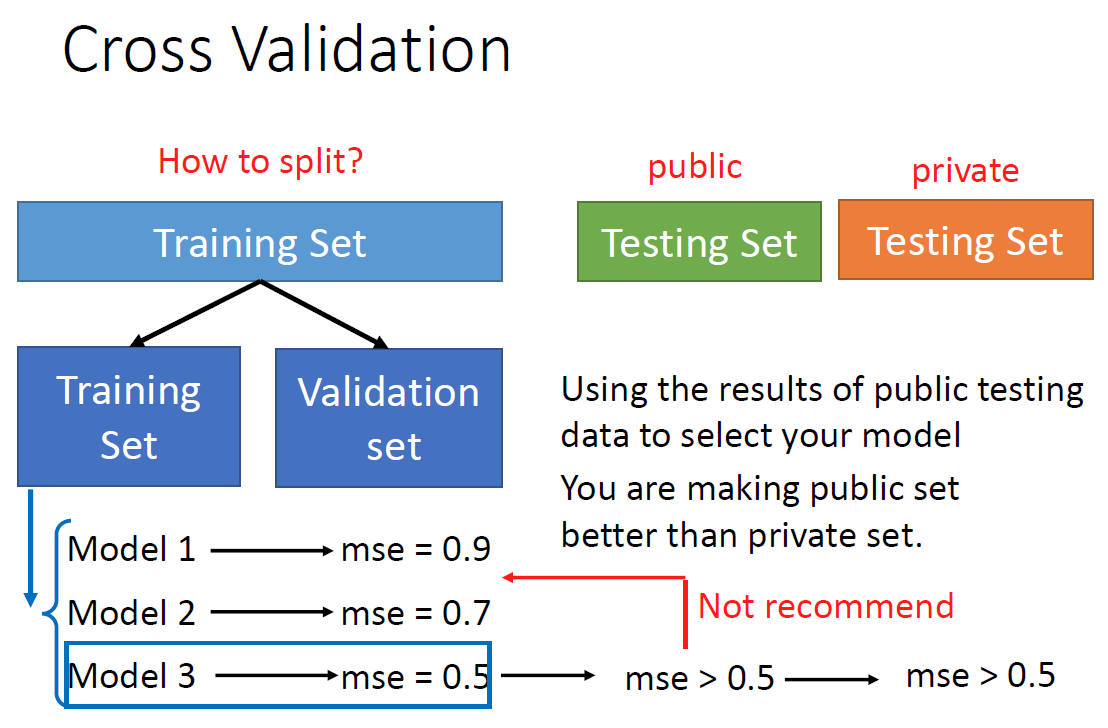
我们将训练集中的数据拿出一部分来进行验证,从而保证最大限度的利用的原始数据集。但是,这就又有一个问题,我们如何进行分组呢?
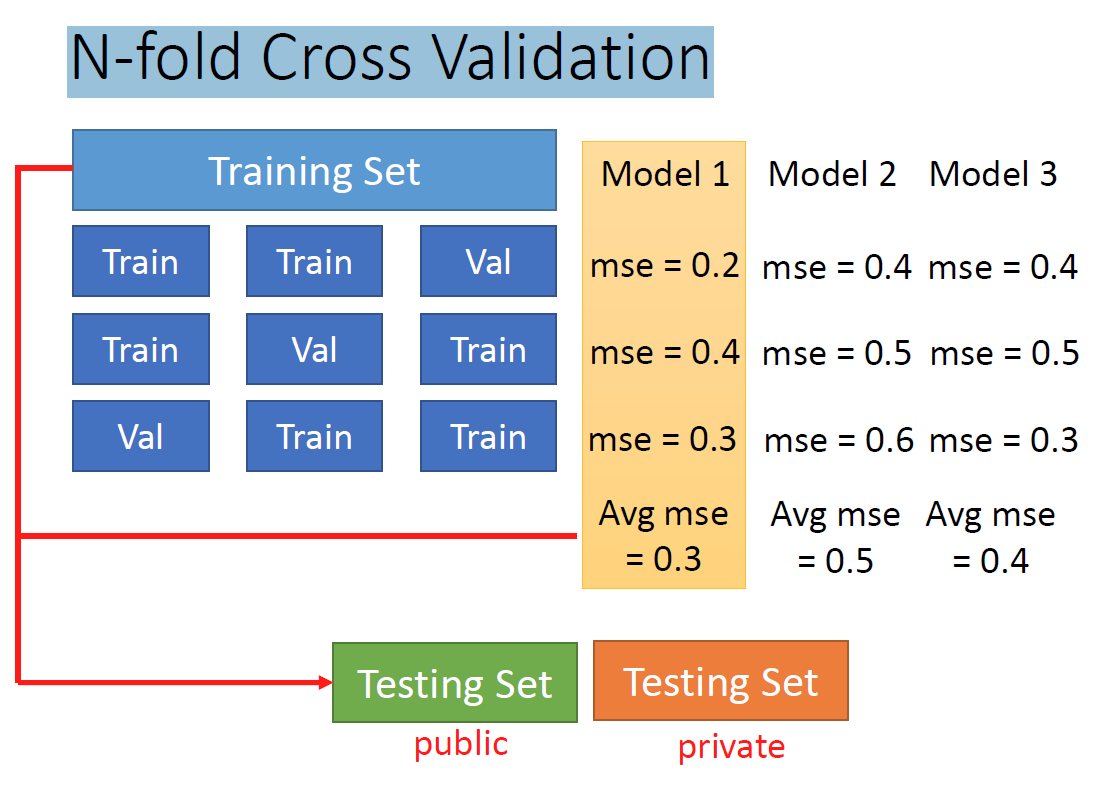
这就是我曾经在Matlab中的K折交叉验证(N fold Cross Validation),我们从下图中可以看到,我们取不同的验证集,不同的模型,可以得到不同的MSE,我们将MSE取平均就可以的到可行性之内的最佳模型,这个模型可以说是很“中庸”,因为它既不会因为Loss太大而失去作用,也不会因为对原始数据的过拟合,导致在测试集上的表现很差。
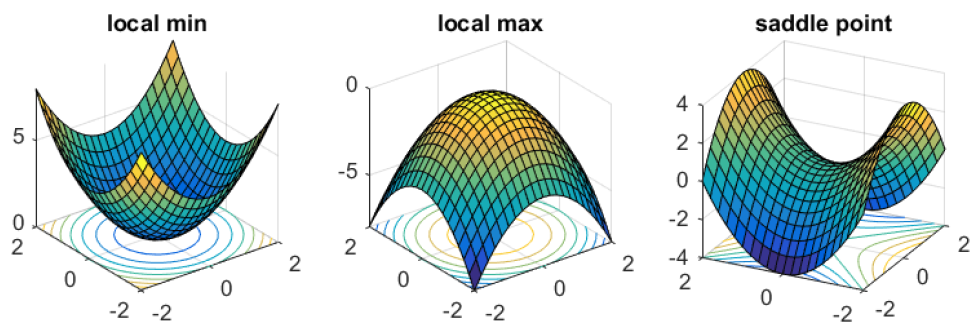
局部最小值与鞍点
我们在迭代模型的时候,使用的方法为梯度下降,而当我们使用梯度下降时的两个所谓的局限性便是:局部最小值与鞍点。
根据高等数学的知识,我们知道鞍点其实不是最小值,他只有两个方向比它高,两个方向比它小。
鞍点
我们先看鞍点,在这个点,我们梯度求解为0,所以我们的计算机不知道像哪边走?但是我们知道其实这不是最小的点。我们如何判断这个点是鞍点还是最小值点呢?
我们只要知道这个点附近的值与他自己的值的比较。是全部都大于它还是有大有小。其实我们只要知道Loss函数是什么样子就能求出来这个点附近的情况。但是Loss函数过于复杂,我们一般不太可能把它写出来,于是我们就是用泰勒逼近,考察一下这个点附近的取值如何。
$$
L\left( \theta \right) \approx L\left( \theta ’ \right) +\left( \theta -\theta ’ \right) ^Tg+\frac{1}{2}\left( \theta -\theta ’ \right) ^TH\left( \theta -\theta ’ \right)
$$
上图中的g是是梯度向量,我们知道在这个点的梯度是0,所以我们的公式便是:
$$
L\left( \theta \right) \approx L\left( \theta ’ \right) +\frac{1}{2}\left( \theta -\theta ’ \right) ^TH\left( \theta -\theta ’ \right)
$$
上图中的H为海瑟矩阵:
$$
H_{i j}=\frac{\partial^{2}}{\partial \boldsymbol{\theta}{i} \partial \boldsymbol{\theta}{j}} L\left(\boldsymbol{\theta}^{\prime}\right)
$$
到现在我们最关注的应该是最右边的这个含有海瑟矩阵的部分,我们进行如下替换,便可得到:
$$
\left( \theta -\theta ’ \right) \rightarrow v
\
\left( \theta -\theta ’ \right) ^TH\left( \theta -\theta ’ \right)\rightarrow v^THv
$$
这个时候我们有:

eigen values:特征值
eigen vector:特征向量
到此为止,我们会判断一个梯度为0的点,到底是鞍点还是最小值点。如果是鞍点的话,我们下一步那是继续下降,不过不能是梯度下降了,那应该用什么办法呢?
其实海瑟矩阵就能完成这个任务,我们需要利用特征向量完成梯度的作用,如下:

在这堂课的最后,老师说了,其实利用这个方法来代替梯度其实不是最优解,因为计算时间很长。
局部最小值
我们在真实的训练情况中,大多数情况下都不会遇到局部最小值,[大部分情况还是鞍点的情况多一点。](Source:https
://docs.google.com/presentation/d/1siUFXARYRpNiMeSRwgFbt7mZVjkMPhR5od09w0Z8xaU/edit#slide=id.g3
1470fd33a_0_33)
下面会说如何对局部最小值进行处理。
训练技巧(Batch & Momentum)
老师上课又重新回顾了一下Batch的概念,然后提出了用每一个Batch中的训练数据与用一整个数据集进行训练的差别,具体如下:
| Small | Large | |
|---|---|---|
| Speed for one update (no parallel) |
Faster | Slower |
| Speed for one update (with parallel) |
Same | Same (not too large) |
| Time for one epoch | Slower | Faster:trophy: |
| Gradient | Noisy | Stable |
| Optimization | Better:trophy: | Worse |
| Generalization | Better:trophy: | Worse |
对了,每一个Batch的大小也是一个hyperparameter。
Momentum(动量),这是物理中的一个描述量,通过这个方法,我们可以减小我们的模型进入局部最小值的概率,因为如果我们的模型梯度下降到最小的梯度的时候,我们还有动量可以进行调整。具象化的图示如下:
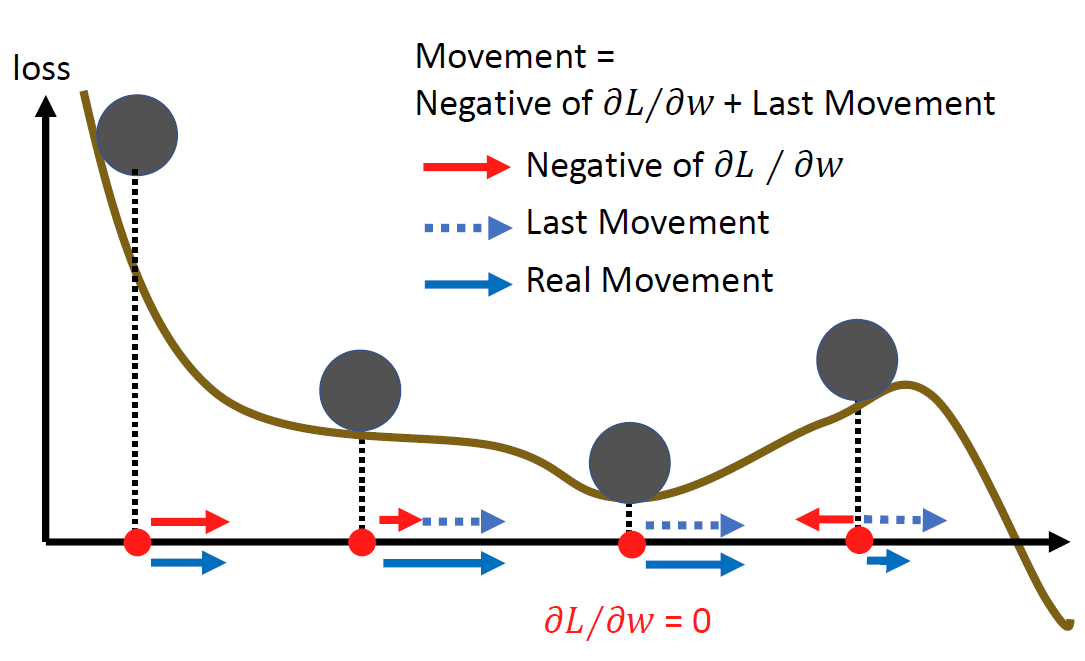
那么用数学的方式来表达是怎样的呢?其实也就是在梯度下降的方向上加上动量:

值得注意的是,我们当前进行下降的判断并不是来自上一步的动量加上梯度乘以学习率。我们通过上图可以看出来,其实是将所有之前的步的动量都累加在一起了。
自动调整学习速率
首先我们以一个简单的例子来说明为什么要动态调整学习速率呢?
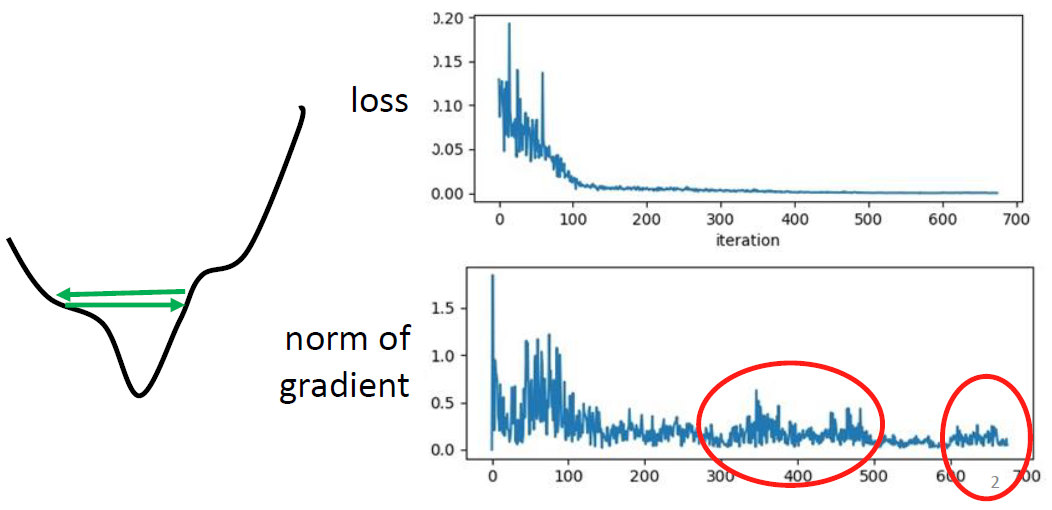
我们看上图的右侧的的Loss,这个时候其实Loss其实已经降得很低了,但这就是我们想要达到的目的吗?如果观察梯度就可以知道这个时候的梯度依旧波动很大,其实这个时候右边的这个图就很能反应状况,我们的学习率太大,导致太两侧的山脊上来回横跳。
那这个时候是不是我们只要调小学习率(步长)就可以了呢?其实不是,如果我们的学习率调的过于小的时候,我们就会发现在这个Error Surface很平缓的地方,我们就很难继续前进。这个时候我们就要引入我们的可变学习率。那么我们学习率的变化的参照是什么呢?我们想要在地形平缓的时候走的快一点,地形陡峭的时候,走的缓慢一点。
我们原先的参数更新过程就会变成:
$$
\boldsymbol{\theta }{i}^{\boldsymbol{t}+\mathbf{1}}\gets \boldsymbol{\theta }{i}^{\boldsymbol{t}}-\eta \boldsymbol{g}{i}^{\boldsymbol{t}}
\
\boldsymbol{g}{i}^{\boldsymbol{t}}=\left. \frac{\partial L}{\partial \boldsymbol{\theta }i} \right|{\boldsymbol{\theta }=\boldsymbol{\theta }^{\boldsymbol{t}}}
\
\downarrow
\
\boldsymbol{\theta }{i}^{\boldsymbol{t}+\mathbf{1}}\gets \boldsymbol{\theta }{i}^{\boldsymbol{t}}-\frac{\eta}{\sigma {i}^{t}}\boldsymbol{g}{i}^{\boldsymbol{t}}
$$
这个时候,我们如何处理学习率下面的这个参数𝜎就成了很重要的问题。
RMS(Root Mean Square,均方根)
$$
\begin{aligned}
&\boldsymbol{\theta}{i}^{\mathbf{1}} \leftarrow \boldsymbol{\theta}{i}^{0}-\frac{\eta}{\sigma_{i}^{0}} g_{i}^{0} \quad \sigma_{i}^{0}=\sqrt{\left(g_{i}^{0}\right)^{2}}=\left|g_{i}^{0}\right|\
&\boldsymbol{\theta}{i}^{2} \leftarrow \boldsymbol{\theta}{i}^{\mathbf{1}}-\frac{\eta}{\sigma_{i}^{1}} g_{i}^{1} \quad \sigma_{i}^{1}=\sqrt{\frac{1}{2}\left[\left(g_{i}^{0}\right)^{2}+\left(g_{i}^{1}\right)^{2}\right]}\
&\boldsymbol{\theta}{i}^{3} \leftarrow \boldsymbol{\theta}{i}^{2}-\frac{\eta}{\sigma_{i}^{2}} g_{i}^{2} \quad \sigma_{i}^{2}=\sqrt{\frac{1}{3}\left[\left(g_{i}^{0}\right)^{2}+\left(g_{i}^{1}\right)^{2}+\left(g_{i}^{2}\right)^{2}\right]}\
&\boldsymbol{\theta}{i}^{\boldsymbol{t}+1} \leftarrow \boldsymbol{\theta}{i}^{\boldsymbol{t}}-\frac{\eta}{\sigma_{i}^{t}} \boldsymbol{g}{i}^{t} \quad \sigma{i}^{t}=\sqrt{\frac{1}{t+1} \sum_{i=0}^{t}\left(\boldsymbol{g}_{i}^{t}\right)^{2}}
\end{aligned}
$$
我们看上述方程的递推,每一步都考虑了以前所有布的情况,如果之前的所有梯度大的话,相对应的在分母上就会使整体下降的便慢,如果之前的梯度小的话,下降的就会快一点。
RMSProp
在上面RMS的方法中,我们没有考虑到就算是同一个参数,它需要的学习率也是随着时间的变化而不同的。我们想要一个可以在同一个参数,同一个方向也可以进行动态调整的学习率。
所以我们提出了第二种方法:RMSProp
$$
\sigma {i}^{0}=\sqrt{\left( g{i}^{0} \right) ^2}
\
\sigma _{i}^{1}=\sqrt{\alpha \left( \sigma {i}^{0} \right) ^2+(1-\alpha )\left( g{i}^{1} \right) ^2}
\
,,\sigma _{i}^{2}=\sqrt{\alpha \left( \sigma {i}^{1} \right) ^2+(1-\alpha )\left( g{i}^{2} \right) ^2}
\
,,\downarrow
\
\sigma _{i}^{t}=\sqrt{\alpha \left( \sigma {i}^{t-1} \right) ^2+(1-\alpha )\left( g{i}^{t} \right) ^2}
$$
我们从公式中可以看出来α是一个Hyper Parameter(超参数),这个参数说明了现在的的梯度相较于以前所有的梯度的重要性,这个参数的取值是0~1,越靠近1,越说明当前的梯度更加不重要。
Adam
其实Adam就是前面几个好的算法的集合:Adam = RMSProp + Momentum这个Adam的算法在Pytorch里了,所以不用过多了解。
Learning Rate Decay
下图是一个椭球,我们从一边下降到最低点,利用RMS算法,我们得到如下图所示的结果:
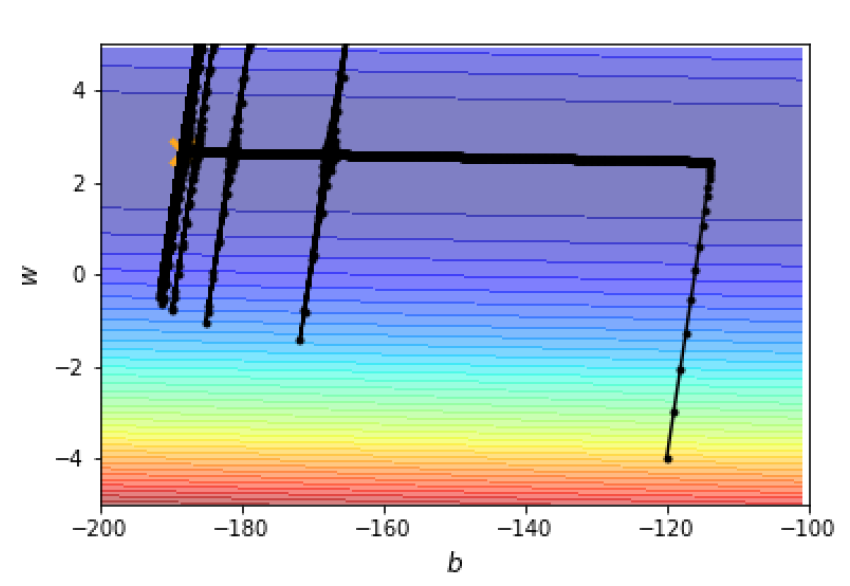
我们可以看到从开始到底部的平坦区域是正常的,然后在底部区域开始了一段时间后,突然有了一场,这是怎么回事呢?我们知道这个算法会累积梯度,所以一开始的时候我们纵向下降时累积了许多梯度的,所以在某一个时间就会有这样的“爆炸的”现象。在最后的时候我们的梯度会在纵向上来回反复,然后横向前进一段时间,又开始了波动,不过最后算是可以到达终点。
有什么方法可以避免这种反复横跳呢?我们可以将学习率与时间进行挂钩,我们知道越到终点,所需要的前面的梯度数据就越少,所以我们将学习率设置成一个函数:
$$
\boldsymbol{\theta}{i}^{\boldsymbol{t}+\mathbf{1}} \leftarrow \boldsymbol{\theta}{i}^{\boldsymbol{t}}-\frac{\eta^{t}}{\sigma_{i}^{t}} \boldsymbol{g}_{i}^{\boldsymbol{t}}
$$
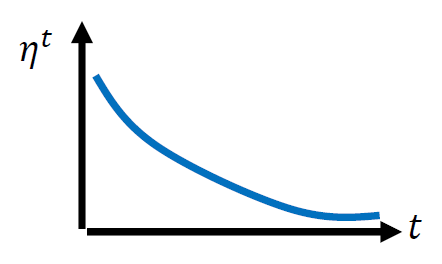
于是我们的图像就不会出现最后左右横跳的无效下降了
Warm Up
用上面方法中将时间与学习率进行关联的方法其实过于简单,我们考虑到在一开始的时候信息量并没有之后的大,所以一开始的时候有一个预热,要多读一些之前的梯度,然后再根据时间进行减少便可以很好的达到训练的目的。这个时候训练率与时间的图像大致为:
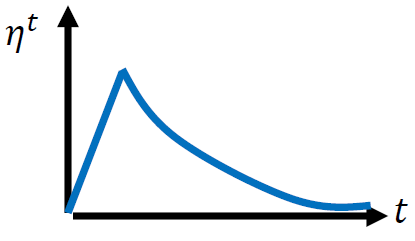
总结来看,我们对梯度下降方法的改进便在三个地方,一个是学习率,一个是均方根,一个是动量。见下图:

Loss函数的选择
如果我们训练的问题时一个分类问题,我们很有可能在训练的时候找不到Loss最小,这个时候我们要考虑使用不一样的Loss函数。通常在分类问题中我们需要的是Cross entropy。
这个函数与原本的MSE(均方差)张这个样子:
$$
\begin{aligned}
&e=\sum_{i}\left(\widehat{\boldsymbol{y}}{i}-\boldsymbol{y}{i}^{\prime}\right)^{2} \
&e=-\sum_{i} \widehat{y}{i} \ln \boldsymbol{y}{i}^{\prime}
\end{aligned}
$$
从下面两个图中我们可以看出来,在使用Cross entropy时,我们的Loss函数更加的连续,所以更容易走到Loss更低的地方去。
Lecture 3
机器学习原理
我们回顾机器学习的基本步骤:
graph TD
A[Step 1: function with unknown ]
-->B[Step 2: define loss]
-->C[Step 3: optimization]
我们以数码宝贝与宝可梦分类器为例。我们需要输入数码宝贝或者宝可梦的图像,输出是一个分类判断。我们观察到宝可梦与数码宝贝的线条疏密程度不一样,而线条又以点构成,我们就可以将图片的边缘处理出来,然后统计黑白点的数目,这样就可以很好的达到分类的作用。
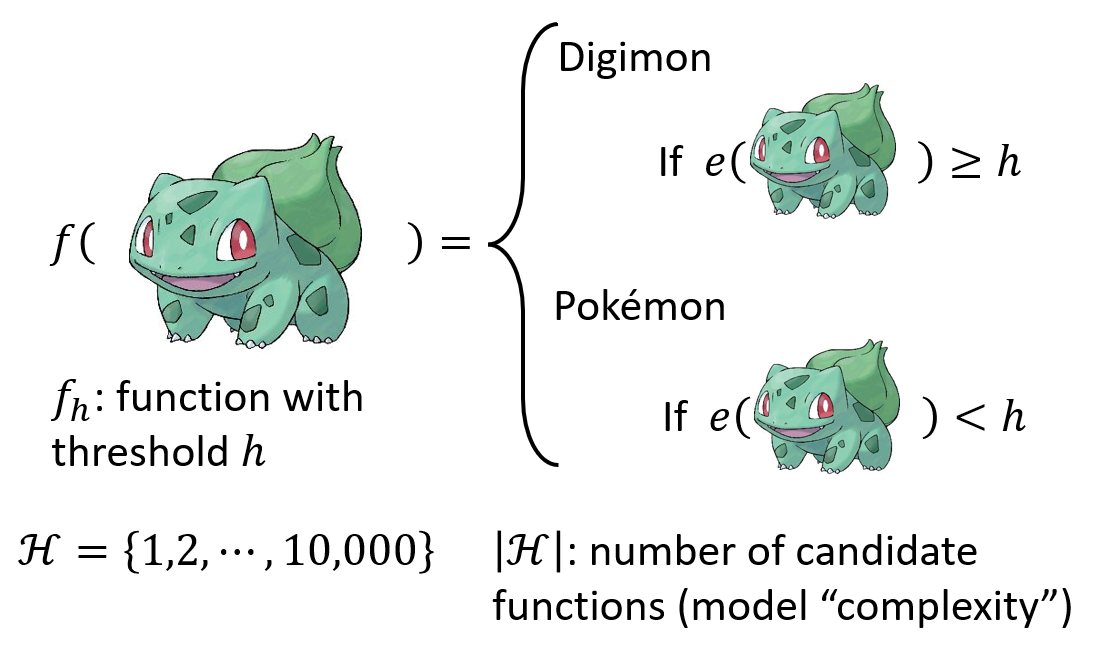
所以我们到这一步就确定了我们的未知函数,如上图所示,接下来,便是我们的参数确定方法即损失函数的确定。我们将损失函数设定成错误判断的累计,有如下函数:
$$
L(h, \mathcal{D})=\frac{1}{N} \sum_{n=1}^{N} l\left(h, x^{n}, \hat{y}^{n}\right)
$$
我们看到这个函数L的里面有一个l函数,这个函数有三个参数,x是数据集D中的图片,y是该图片所对应的正确的生物。所以我们可以得到这个三个参数的函数为:
$$
\text{If } f_h\left( x^{\mathrm{n}} \right) \ne \mathrm{\hat{y}}^{\mathrm{n}},, \text{ , } \text{Output 1}
\ \text{Otherwise , Output 0}
\
$$
在这个函数的选择上,我们也可以用cross-entropy 但是为了方便,我们还是使用上面的方法定义Loss。
我们再来看训练集相关的事情,我们假设可以收集到全宇宙的宝可梦与神奇宝贝,我们就可以将这些收集到资料,进行训练。之后就会得到理想的参数选择,我们设为h:
$$
{\color{red} h^{all}}=\mathrm{arg}\min_h L\left( h,{\color{red} \mathcal{D} _{all}} \right)
$$
但去掉这个假设,其实我们不能得到所有宝可梦与数码宝贝的图片,因为会出新的生物。这个时候,我们只有部分训练资料,我们进行训练,这个时候我们可以得到:
$$
{\color{blue} h^{\mathrm{train}}}=\mathrm{arg}\min_h L\left( h,{\color{blue} \mathcal{D} _{\mathrm{train}}} \right)
$$
我们所希望的是这个h-train尽量的靠近h-all。我们自行设置一个阈值,如果这两者之差小于这个阈值我们就认定这个模型好:
$$
\text{We want } L\left( {\color{blue} h^{\mathrm{train}}},{\color{red} \mathcal{D} _{all}} \right) -L\left( {\color{red} h^{all}},{\color{red} \mathcal{D} _{all}} \right) \le \delta
$$
这个时候我们探究哪一种D-train可以满足条件,我们验证发现存在一个h满足如下规律:
$$
\forall {\color{green} h}\in \mathcal{H} ,\left| L\left( {\color{green} h},{\color{blue} \mathcal{D} {\mathrm{train}}} \right) -L\left( {\color{green} h},{\color{red} \mathcal{D} {\mathrm{all}}} \right) \right|\le \delta /2
$$
数学证明如下:
$$
L\left(h^{\text {train }}, \mathcal{D}{\text {all }}\right) \leq L\left(h^{\text {train }}, \mathcal{D}{\text {train }}\right)+\delta / 2
$$
$$
\leq L\left(h^{a l l}, \mathcal{D}_{\operatorname{train}}\right)+\delta / 2
$$
$$
\leq L\left(h^{\text {all }}, \mathcal{D}{\text {all }}\right)+\delta / 2+\delta / 2=L\left(h^{\text {all }}, \mathcal{D}{\text {all }}\right)+\delta
$$
我们将满足上面的这个式子叫做好的训练资料,把没有满足上面这个式子的叫做坏的资料,然后我们将其分成一个个训练集,在下图中蓝色是好的训练资料,橙色是坏的训练资料:
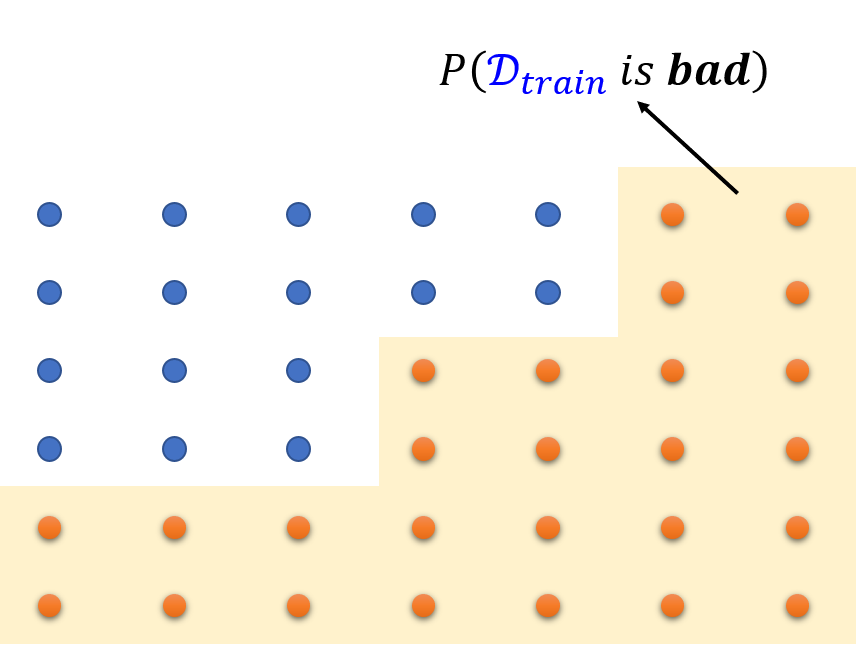
我们想要知道所有坏的数据所占的比例有多大,如果一个点一个点算会太麻烦。我们在一片区域中,只要存在一个可以弄坏数据的h我们就称之为坏数据,所以我们可以有以下范围的框定:
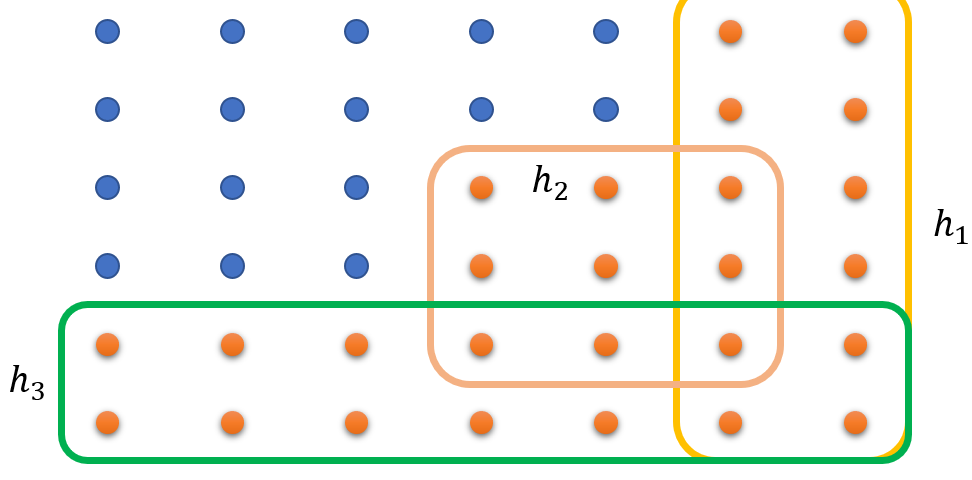
我们可以看到每个区域的概论是可以算出来的,比如说h1区域的概率就是以h1为参数的L(h,D-train)的概率。考虑到每个区域的概率是由重叠的,所以我们不能直接将各个区域的概率相加,所以我们取并集。而该并集一定小于所有概率面积之和。
$$
\begin{aligned}
P\left(\mathcal{D}{\text {train }} \text { is } \boldsymbol{b a d}\right) &=\bigcup{h \in \mathcal{H}} P\left(\mathcal{D}{\text {train }} \text { is bad due to } h\right) \
& \leq \sum{h \in \mathcal{H}} P\left(\mathcal{D}{\text {train }} \text { is bad due to } h\right)
\end{aligned}
$$
有统计学概率的知识,我们可以得到:
$$
\begin{aligned}
&\leq \sum{h \in \mathcal{H}} 2 \exp \left(-2 N \varepsilon^{2}\right) \
&=|\mathcal{H}| \cdot 2 \exp \left(-2 N \varepsilon^{2}\right)
\end{aligned}
$$
我们如何要让这个P(D-train is bad)尽可能的小呢?有两种方法:第一种是缩小|H|,即缩小可以选择的方程的数目(别忘了前面所讲的H的意义)。第二种是增加N即增加训练资料的数目。
但我们发现这两种方法其实是鱼与熊掌不可兼得的方法,如下图所示:
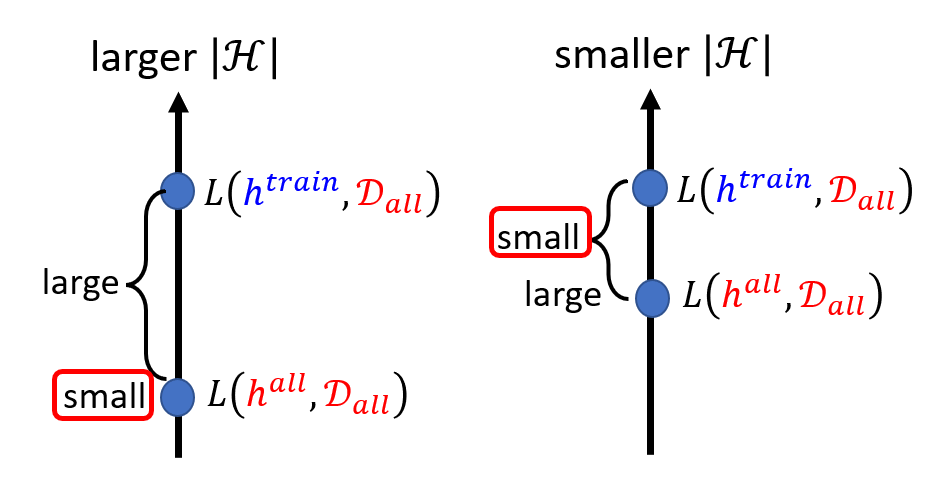
而我们如何做到鱼与熊掌兼得(调参)呢?深度学习!!
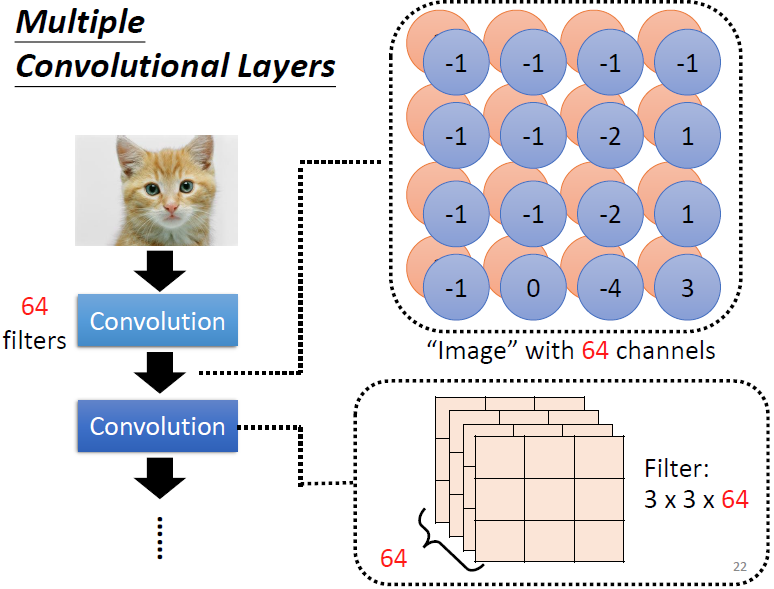
卷积神经网络 (Convolutional Neural Networks, CNN)
第一种理解方式(神经元版)
卷积神经网络是为图片设计的神经网络,当然不是说只能用于图片,我们等会会提到。首先我们假设有一张100x100的图片,我们需要识别这个图片,那么我们就需要将其转化成Tensor,我们就需要将图片分成RGB三个通道,每个通道都有100x100的数字。如下图所示:
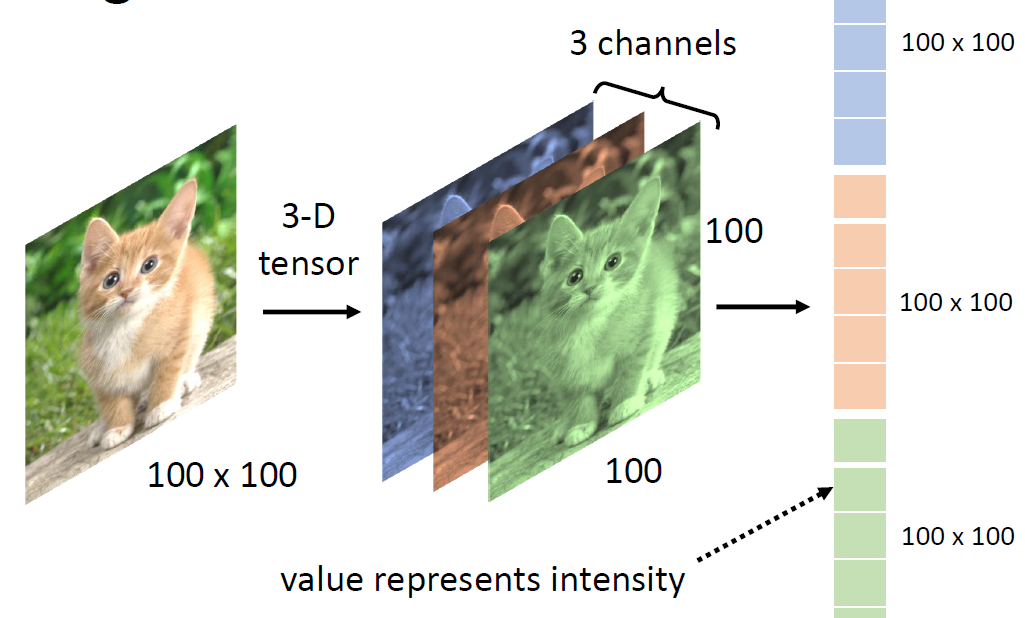
我们将这三个通道的所有数据都拉长放入一个列向量里面。按照通常的处理方法我们接着需要进入Fully Connected Network,但是我们仔细想想就会发现,如果要是别图中的物体是什么的话就需要将这个物体的特征识别出来,这个特征肯定不是整张图片,这样我们就可以将一部分神经元负责一部分。我们人类其实也是这个方法去辨识物体,我们观察物体的特征,然后做出判断。

针对这种特性,我们让每一组神经元只观察部分(Receptive field):
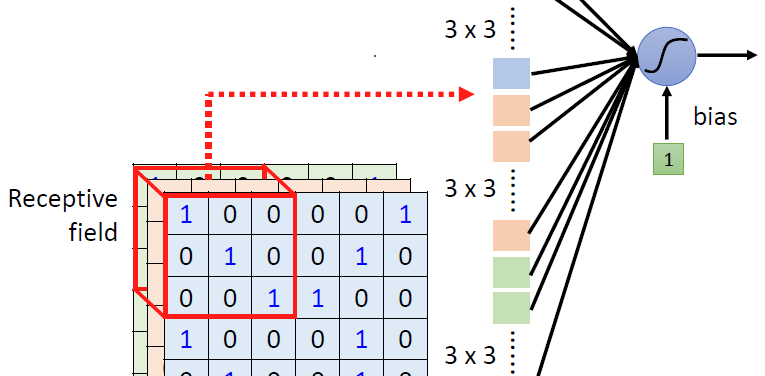
不同的Receptive field可以有重叠(overlapped),因为如果一个特征在两个区域的交界处就不能很好的起到检测的作用。在CNN中我们通常来说都会去看三个通道的数值,所以我们在描述的时候只描述它的平面数值。我们在一次检测中平移这个Receptive field,每次移动的步长我们叫做:stride,我们从开始移动到结束的时候,我们去考虑移动结束的时候,有的时候不会是完全的覆盖,会超出去一部分,我们把超出去的这一部分就叫做:Padding,而Padding的填充方法有很多,常见的是全部补充成0,或者全部区域取平均,或者部分区域取平均。
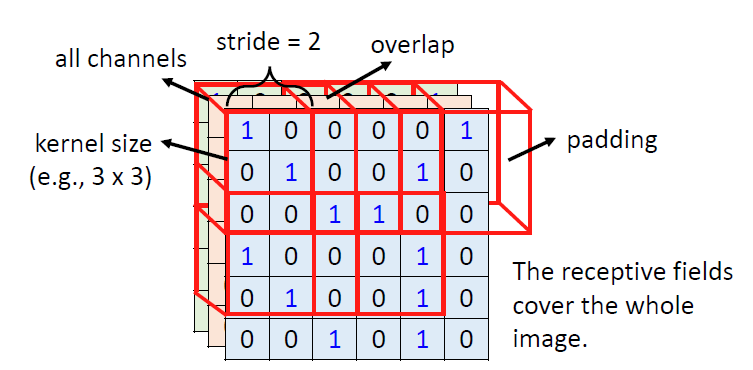
我们继续思考,在同一张图片,每一图片的不同特征很有可能出现在不同的区域,比如说一张景点打卡照,要检测其中的人脸,但人脸不一定出现在完全相同的区域。
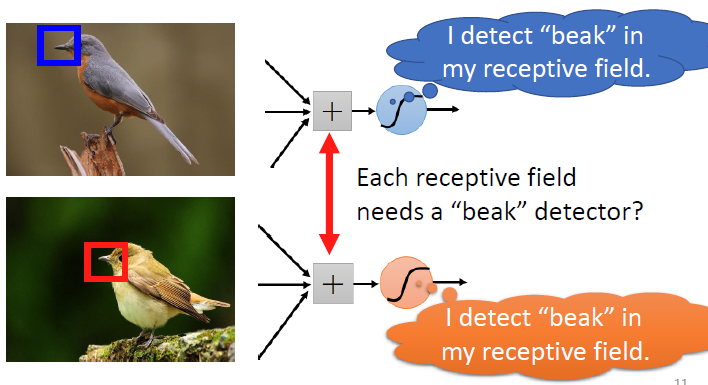
这就引入了我们的下一个概念:共用参数
在最开始我们不同的区域是为了检测物体的特征,现在我们共用参数,即将不同Receptive field传递到神经元的权重设为一致,这是一种将模型的伸缩性减少的方法,但是对于图片的检测即为有用。需要注意的是,我们共用参数,但这不代表神经元输出的值完全相等。其实我们每一组Receptive field其实对应了一组参数,而我们把这些参数叫做:Filter
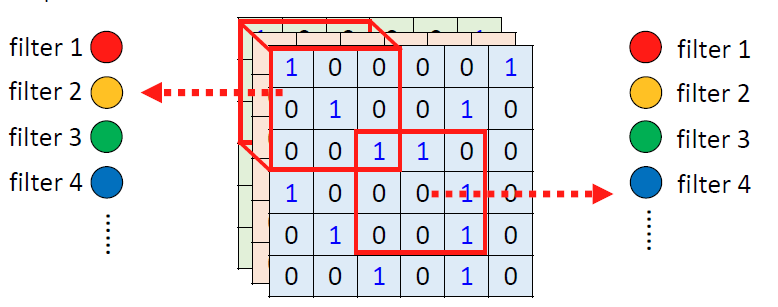
说了这么多,我们来总结一下,Fully Connected的网络弹性是最大的,但是对于特定领域的识别是由缺陷的,而我们加入Receptive Field,进一步减少了模型的弹性,而最后一步的Parameter Sharing更是限制了它的弹性。
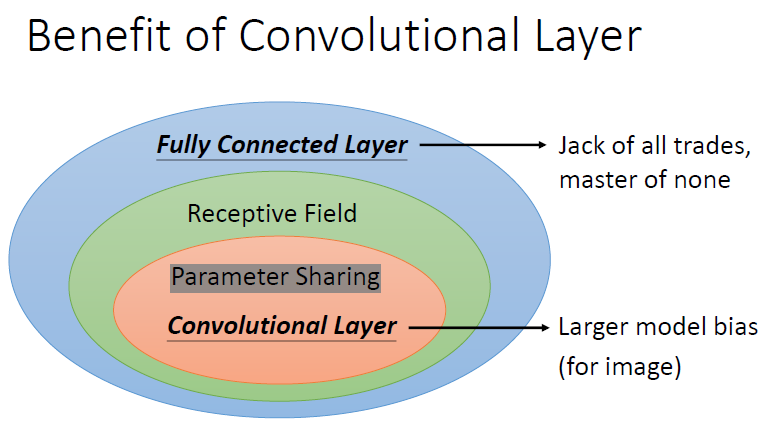
第二种理解方式(过滤器)
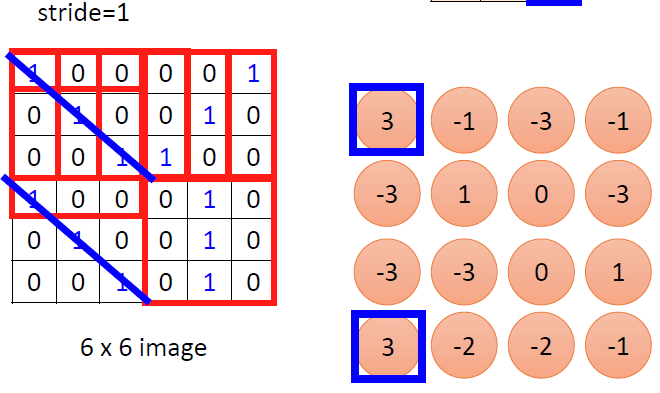
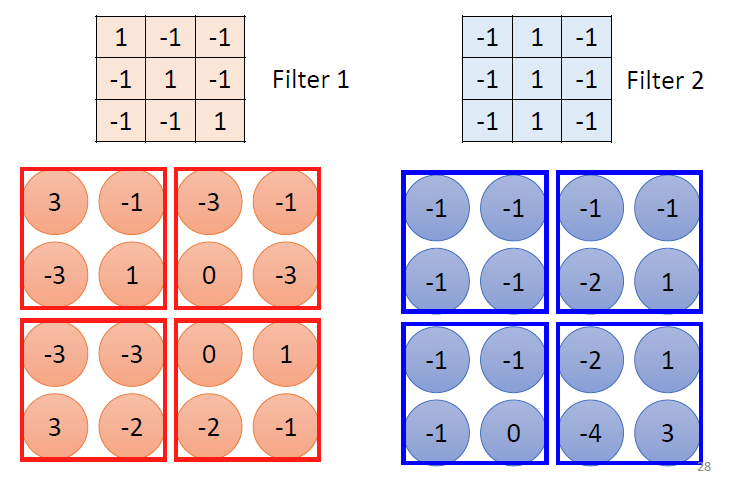
我们先假设图片都是两个通道的,我们假设有很多过滤器(Filter),去扫面整张图片,我们的过滤器里面就装着图片的部分特征,如鸟嘴部分或者人脸部分。我们把这个过滤器放在图片的各个位置上相对的位置做内乘(Inner product),我们就能的到一个数值,这个数值越大呢,就代表这个区域与filter越相似。
这只是一个过滤器的结果,我们有多少个过滤器就可以叠多少层,我们把这个处理的结果叫做:Feature Map。其实我们折磨处理完,还是一个“图片“,只是这个图片不是三个通道而是上一个卷积层的Filter数目。通过这个方法,我们可以叠很多的卷积层:
两个理解方法的对比
| 神经元版本 | 过滤器版本 |
|---|---|
| 每个神经元只考虑一个感受区域 (receptive field) |
有一组过滤器检测小的模式 (patterns) |
| 不同的神经元感受区域参数共享。 | 每个过滤器卷积在输入图像上。 |
其实是一样的。
要额外提一下的方法是:Pooling。实际上是一种化简,如下图所示:
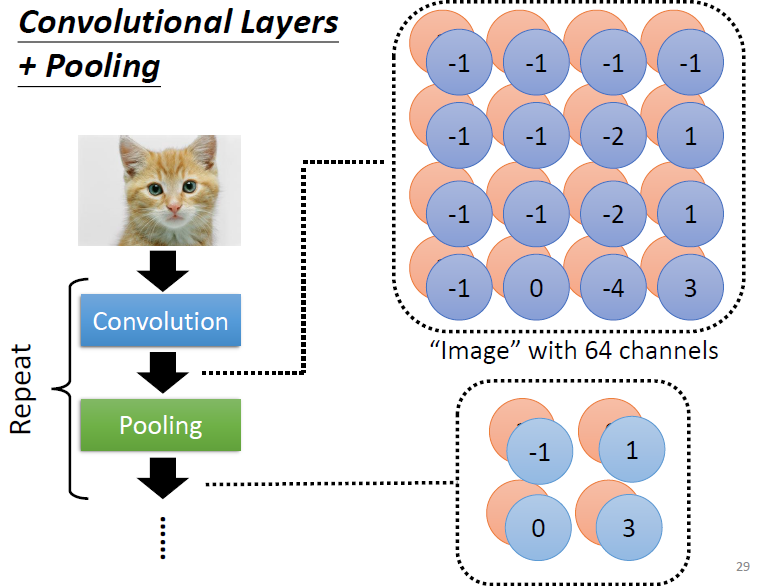
我们知道不同的图片如果把所有的像素拿掉一半的话,其实图片的特征大概率还是存在的,所以我们每次Polling的时候就选取一片区域然后对该区域进行一个运算(取最高或者取平均),传导到下一层。但polling存在的理由很大一部分是因为,为了节省计算的资源,但在今天也是有很多模型没有Polling的。
Lecture 4
自注意力机制(Self-attention)
基本模型框架
我们前面所说的所有深度网路模型都是基于一个向量输入,但是无法处理多个向量输入的问题,如不同图片像素的处理,不同语句文段的处理。要处理以上的信息需要有多个向量输入。再说输出的类型,我们常见的输出是,给模型喂入N个向量,结果返回N个结果,这些结果可能是类别或者数字或者其他类型。也有可能输出一个类别或回归结果,最后还有一种可能是输出不定类的结果个数。
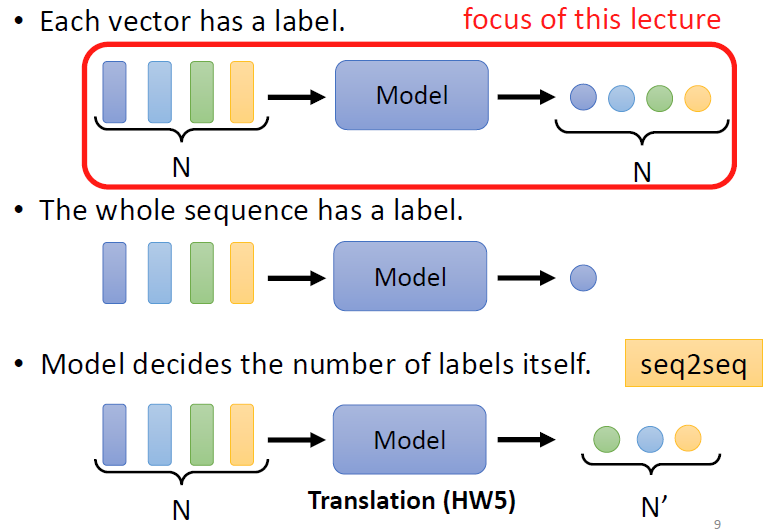 我们着重学习关于N个输入,然后输出N个结果相关的问题。对于这种输入与输出数目一样多的类型我们叫做:Sequence Labeling。我们在HW2中对于每一段语音讯号,我们对前后的单词都作为输入的向量,以此来考虑其他输入对于本输入的影响。这种方法也有局限性,如果像是HW2中的如果我们考虑所有Sequence也足够,因为一个Sequence足够小,显然这种方式不是一种很好方法,因为如果我们的Sequence足够长的话就会很棘手。我们需要一个新的方法来考虑所有的Sequence。
我们着重学习关于N个输入,然后输出N个结果相关的问题。对于这种输入与输出数目一样多的类型我们叫做:Sequence Labeling。我们在HW2中对于每一段语音讯号,我们对前后的单词都作为输入的向量,以此来考虑其他输入对于本输入的影响。这种方法也有局限性,如果像是HW2中的如果我们考虑所有Sequence也足够,因为一个Sequence足够小,显然这种方式不是一种很好方法,因为如果我们的Sequence足够长的话就会很棘手。我们需要一个新的方法来考虑所有的Sequence。
新的方法就叫做:Self-attention
对于以前的方法是直接把所有的Sequence通过一个Fully-connect的Network。那如果我们加一层让他考虑所有的input再通过FC就可以处理我们前面的问题。当然我们通过FC中的得到的结果可以继续通过一个Self-attention考虑所有的Sequence。
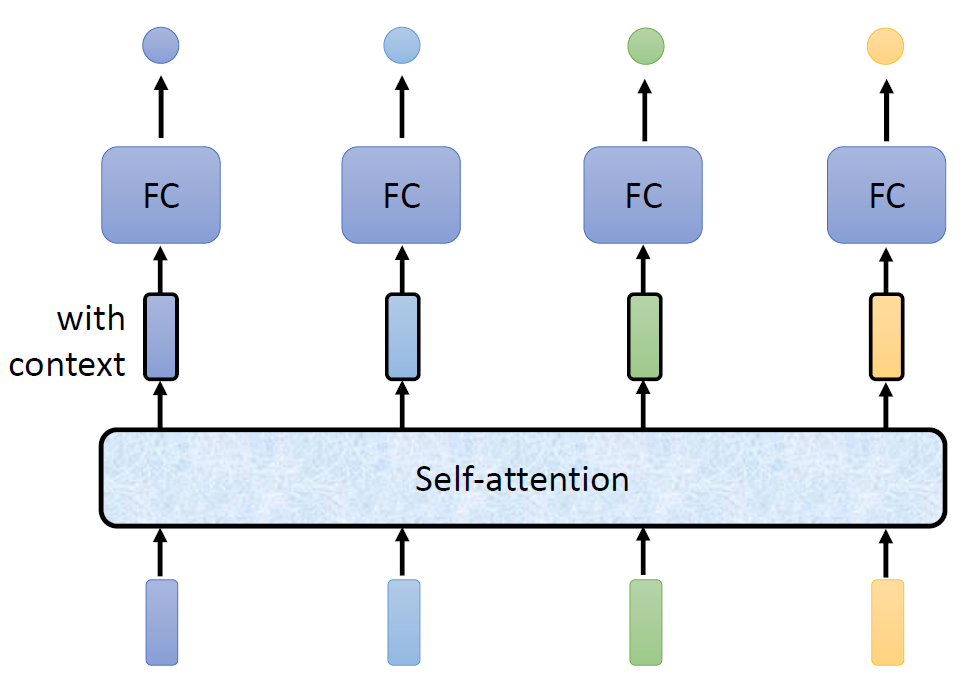
接下来我们探究这个Self-attention是如何运作的。我们以输入a1为例,我们首先需要考虑的就是a1与其他向量输入的关系。因为我们说过我们不可能考虑一整个Sequence所以我们要有所侧重,考虑重要的vector忽略不重要的。往下一步就是如何决定两个向量之间的关系的问题。
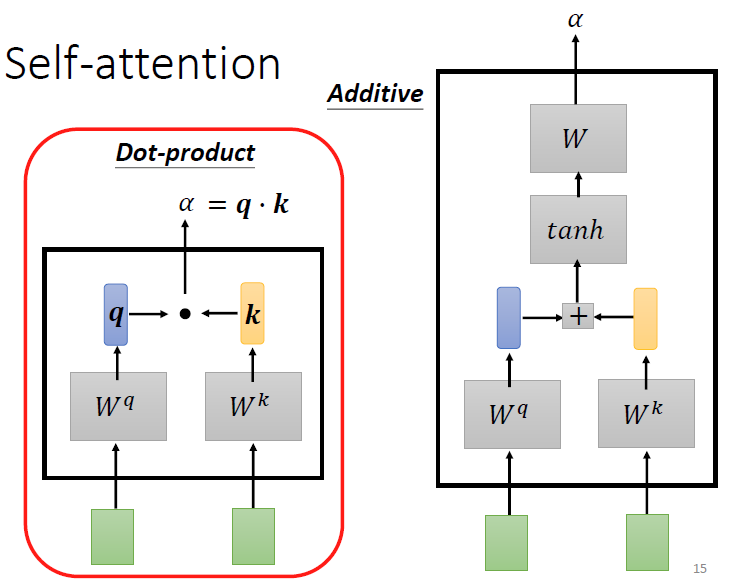
比较常见的处理方法有两种:第一种是Dot-product,第二种是Additive。
我们常用的是点乘,也就是Dot-product。我们先对两个输入的向量乘以一个矩阵,对于结果点乘。而第二种方法就是对于矩阵相乘完了之后进行相加之后经过一个激活函数tanh最后过一个transform。
不管哪一种情况我们最终得到的这个数值我们就称为attention score。对了,我们在计算相关度的时候,也要计算对于自己的相关度。
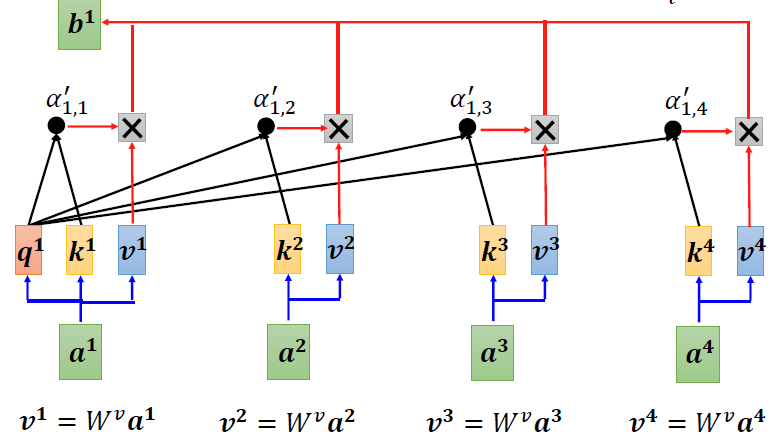
当a1得到了所有的attention score之后会进行一个Soft-max。当然不一定用这个激励函数,也可以用别的。再往后我们就要利用这个经过激励函数的attention score进行计算关联。
接下来我们对于所有的input乘以一个矩阵,然后分别于每个经过激励函数的attention score进行相乘,再把他们所有的都加起来得到b1。
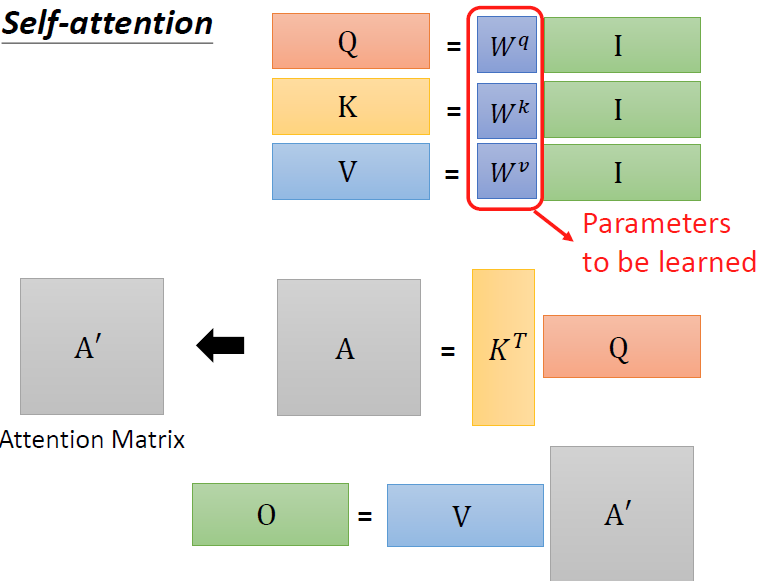
我们从线性代数的角度来看这一系列的过程,其实就是对input做一系列的矩阵变换,得到output。计算机则需要帮我们确定我们的W矩阵。
改进版本
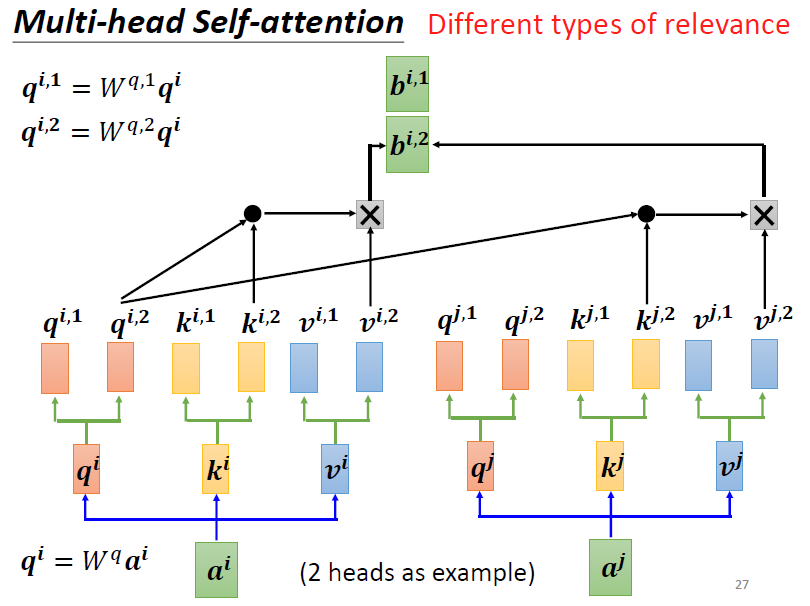
我们有一个改进的版本,即对于每个q,k,v产生两个分支,再让这两个分支的b通过一个W矩阵,得到最后的b。
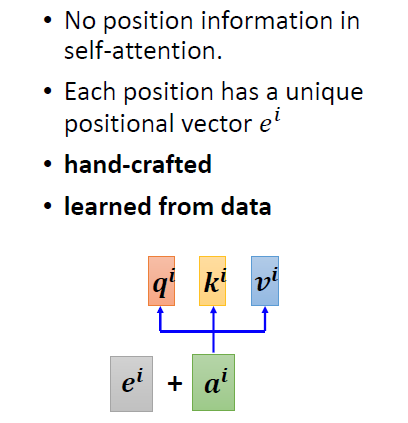
我们回顾上面的模型,我们发现我们并没有考虑input顺序(位置的信息),我们上面的a1,a2,a3只是一种标注,我们并不知道a1于a3之间的距离是否大于a1到a2。没有存在谁在sequence的最前面或者最后。所以我们对模型要输入Positional Encoding,即对于每一个input a,都有一个向量的加入。每一个不同的位置都有它专属的位置。对于Positional Encoding的方法各有不同还是一个待解决的问题。